I tackle the issue of digital content disappearance. Inspired by the concept of a palimpsest, I analyze how digital layers of information are successively replaced and how important contents can vanish from our digital world. The article uncovers the secrets of Google's algorithms, shedding light on their impact on the availability and visibility of information online.
Table of Contents
The relentless, real-time tsunami of information creates perfect conditions for the spread of false stories, theories, conspiracy narratives, and leaks. Cognitive biases and mental shortcuts facilitate their further transmission. (Loc 1802) Ronald J. Deibert Wielka inwigilacja. (this is translation from polish edition)
Today’s post was inspired by reading several books, which I’ll mention, and listening to interviews including one with Piotr Pytlakowski, who wrote The Zone of Oblivion about the disappearing and erasing of the history of Polish Jews. I remember being in the Balkans and asking locals about empty spaces in the village or abandoned decaying houses. They replied: we don’t know, they left. Of course, most of these people were massacred during the ethnic cleansing of the war in former Yugoslavia. Our entire culture is based on tradition and memory, and what is silenced and repressed fades away. Observing the sudden technological leap, changes in information-seeking habits, and also in information dissemination, I began to ponder the phenomenon of disappearance in the digital world.
In today’s post, I would like to discuss the problem of content diversity disappearing in the context of search engine algorithms. These algorithms, becoming a primary source of information for many, present content in various ways. By delivering specific meanings, algorithms become tools that interpret the world. Here, I analyze how their embedded behavioral mechanisms predict our motivations and how the network of meanings they create realizes a certain interpretation. They throw us into a semantic bag of meanings that might suit us, but these are the result of the algorithm’s workings, not our own reasoning. Another issue I will address is the hiding or erasing of vast swathes of information from the Internet, which I refer to as disappearance. This is a very dangerous and fascinating phenomenon, which we will examine in a technical context, hopefully understandable to a layperson. I invite you to read on.
The Disappearance of Information on the Internet - Examples of Vanishing Content and Digital Erosion
Increasingly, I find it difficult to search for older information that I saw on the Internet even 10 years ago. This includes events or people from 20 years ago in my hometown of Wrocław, and to my surprise, I couldn’t find them at all. These were artistic events, facts, various scandals, or scientific articles. I also know of blogs from the period 2005-2008 which have left no trace despite being very popular, and some were even mentioned by nationwide weeklies.
I found only a few discussions on Reddit where people complained that they no longer have access to the contents of these blogs, and that no one made a full dump of the pages, so they have completely disappeared without leaving any trace… How is this possible? Today, we will consider the forms of collective memory and disappearance in the context of information delivered on various media but also through Google. But before we get to search engines and algorithms, let’s think about what digital memory erosion, content disappearance, and the intentional silencing of facts in collective consciousness are? What are the risks and potential threats? Let’s explore the various ways of erosion.
Digital Memory Erosion
In today’s article, we will analyze this problem. Each of us has encountered disappearing information on the Internet. Information can change its position, and over time, due to changes in algorithms, it can become more difficult to find. It can also be completely removed for technical reasons. Let’s first discuss the technical reasons for the disappearance of information, among which the most obvious include:
The expiration of domains, and consequently their removal from the Google index - if the domain no longer exists, we not only lose access to the source, but also after some time to the source’s duplicate in the Google index, and the content disappears.
Deleting web pages for mundane personal reasons, financial but also technical reasons such as lack of software support leading to decision-making by authors to shut down a project. In the case of the disappearing scientific journals analyzed below, it was the business model based on pay-for-access and the failure to reach a revenue threshold that led to the downfall of the service and the disappearance of content. Let’s also be realists. IT and website maintenance can sometimes be serious costs.
Common causes also include simply data loss caused by human error, hacker attacks, or media damage. The burning of the OVH data center, where production and backups were located in the same place, showed administrators and creators holding data there that clouds are real and prone to failures.
By creating a new version of a website, we do not ensure content continuity and do not migrate old data to the new site, we delete content and do not re-index URLs correctly - partially Google fixes this through the reindexing process, but if the content is gone, it does not direct its clients to wrong links and removes them from the index.
If there are not many mentions in mainstream media with citations, the information also disappears. Here is an analogy to forgetfulness and silencing, where historians have a problem reconstructing facts because they lack sources. So, this is some form of digital exclusion and erasure - if you’re not quoted and commented on, you don’t exist. The popularity algorithm, which we will talk about, also plays a role here, analyzing popularity.
Erosion of Media and Data from Servers
Many people interested in data privacy idealize the belief that “nothing gets lost on the Internet”. However, it must be clearly stated: by fetishizing the permanence of data, we create a myth based on an unrealistic perception of reliability and trust in data storage methods. This is a ludicrous statement and completely out of touch with reality! Consider, for example, the real challenges associated with costs, data management, servers, and changes in the ownership of companies responsible for these data.
A layperson believing in such a myth will later be very surprised when, for instance, a service maintaining photographs deletes all their pictures. This happened after Flickr was acquired by SmugMug, when a change in the usage policy of the service resulted in the deletion of 63% of photos and images stored on the servers. Surveillance Capitalism offers in return for our data the possibility to use services for free, but this is also subject to terms and conditions stating that data is not safe in the sense that their integrity is not guaranteed and can disappear at any moment. And indeed, they have disappeared more than once.
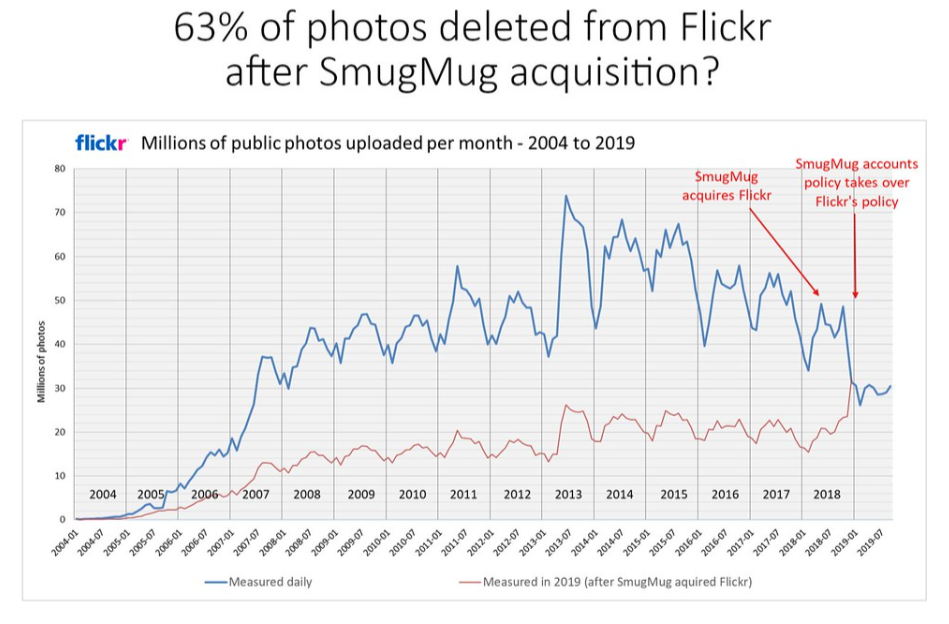
Flickr is also responsible for the accidental deletion of user photos, a problem that has also occurred multiple times with Google, for example, through the incorrect application of compression algorithms. There have also been instances of artifacts appearing on older photos - Google, however, explained that this was also caused by compression. The internet is replete with stories of users who have lost their original photos due to faulty importing tools, engineering errors in data centers, or improper migration. Flickr accidentally “permanently” deletes user’s 3,400 photos | Digital Trends and UPDATE: Flickr User Says Site Deleted 4,000-Picture Account | PCWorld Don’t migrate Flickr photos to SmugMug » (colinpurrington.com)
Erosion of Multimedia and Physical Media
The problem of erosion is not limited to information stored on servers but also extends to films, images, and multimedia. A case in point is the disappearing movies and series, which for various reasons have been not just hidden but completely withdrawn from streaming services. They are subject to disappearance, and sometimes new political correctness or the particular interests of shareholders can lead to their erasure from the catalog without any possibility of access. Disappearing Content: Media is still getting wiped today | Watch | The Take
To this, we can add all physical media such as old floppy disks, cassette tapes, CDs, DVDs, BluRays, etc. CDs are made of layers of polycarbonate, aluminum, gold, silver, or another metal and lacquer. Over time, these layers can undergo chemical degradation, often as a result of oxidation, which ultimately leads to data loss. In CD-Rs, where data is recorded using a special dye that reacts to laser light by changing its color, the dye itself can also degrade over time. Additionally, the reflective layer (usually made of aluminum) can corrode, leading to data loss as well. If you’re holding your CD collection with tears in your eyes, you’re not alone…(thanks to @wikiyu@infosec.exchange from the fediverse for drawing attention to physical media and their disappearance)
Disappearing Academic Publications, Blogs, and Institute Websites
Fortunately, I do not have to present you with a tedious analysis of the index to prove that things disappear because there are already serious articles and academic dissertations addressing this problem. From an article in Nature published in 2020, we learn that over the past 20 years, more than 174 scientific journals have disappeared from the Internet (source). Irretrievably! Most of the disappearing journals from the analysis were in the field of social sciences and humanities (RIP!), but natural sciences, medical sciences, physical sciences, and mathematics were also represented. Eighty-eight journals were associated with a scientific society or research institute. Most of the disappearing journals vanished within 5 years of the services ceasing to publish articles. About one-third disappeared within a year of their last publication.
One might say, what’s the deal, surely good publications will always stand their ground. However, this is not entirely agreeable. Knowledge and cited sources should not disappear. Besides, supposedly nothing gets lost on the Internet, right? As I described earlier in the technical reasons, it was precisely the lack of funding in the pay-for-access model and the failure to generate sufficient revenue, along with the rising IT costs and publishing competition, that led to the downfall of many publishers or institutes. Here’s an interesting ricochet: the disappearing journals in the paid model fell victim to Open Scientific Resources, which are free, increasingly numerous, and more attractive than closed and paid resources. źródło: Open is not forever: A study of vanished open access journals
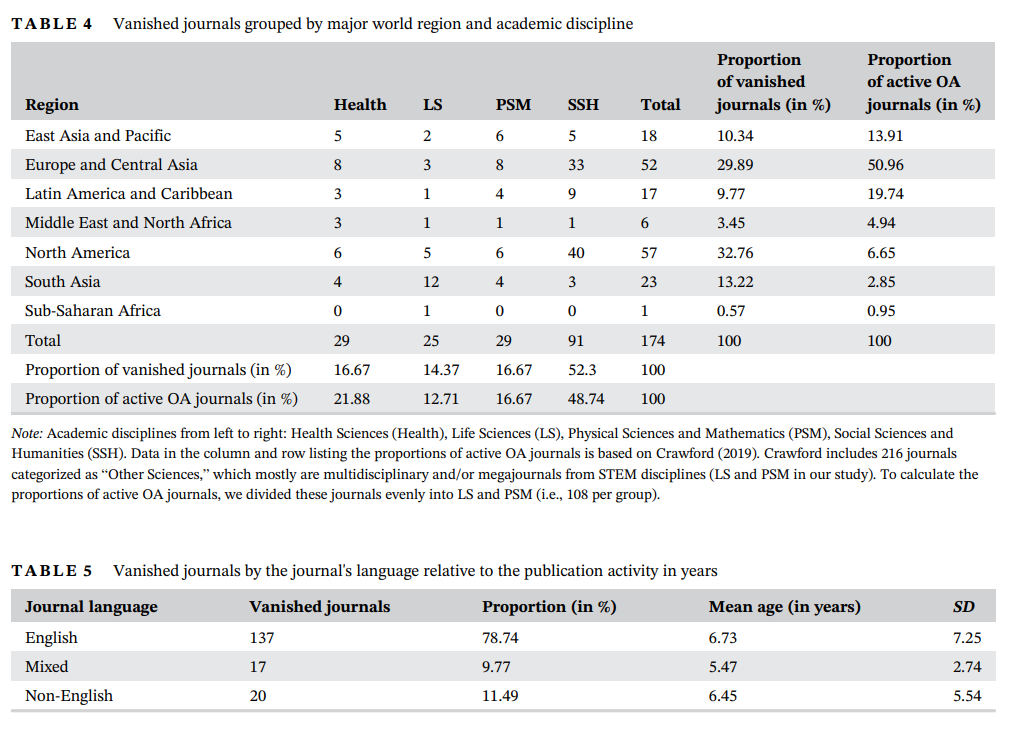
Image source Open is not forever: A study of vanished open access journals
The Disappearance of FLASH
At the end of 2020, Microsoft announced that it would no longer support Flash technology in its browsers. Other browser developers like Google Chrome in July 2019, Mozilla in January 2021, and Safari in September 2020 followed suit. A vast array of internet resources in the form of websites, animated content, and games vanished. I personally service a client who had an eco-friendly game for children in Flash, which functioned until the moment FLASH ceased to be available and runnable without specialized knowledge. Most importantly, few will choose to run flash content due to the lack of security updates. Those who did not convert their games, websites, and animations to new formats have been excluded. And so, the eco-friendly game is no longer available to children. Read more about this topic in Goodbye, Flash on Google Search Central Blog w Google for Developers
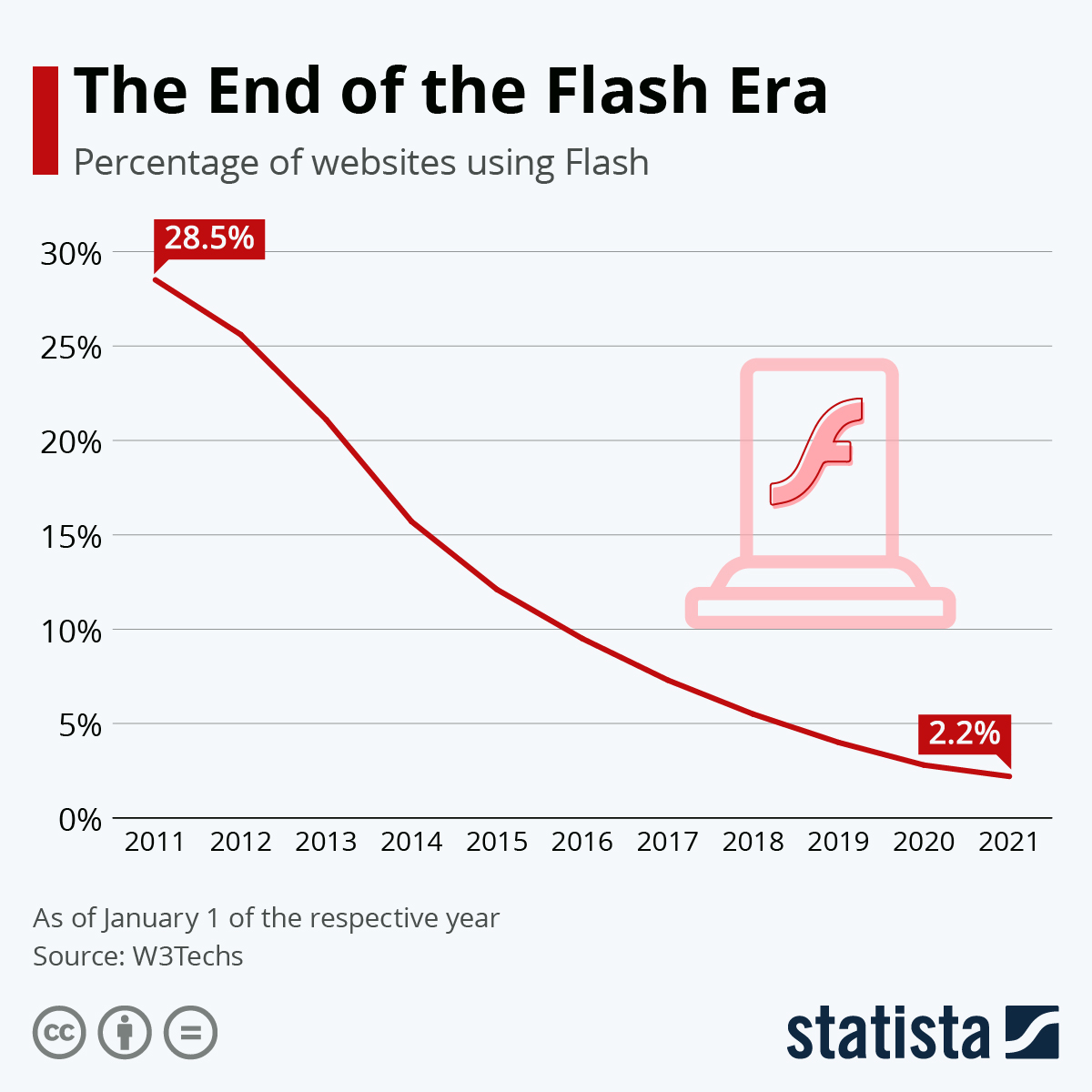
The End of an Era – Next Steps for Adobe Flash - Microsoft Edge Blog (windows.com)
Google Index as a Digital Palimpsest
A palimpsest is an ancient manuscript written on material that was used before; in other words, someone scraped off or removed the previous text to then apply another layer of text on it. Today, I will use the analogy of palimpsests as it helps in explaining the complex problem of disappearing information on the Internet. The index of the Google search engine has transformed into a central resource of humanity’s collective memory, being an authoritative repository of knowledge and information of significant repute. Thus, we will address the significance of memory and access to information for society and individuals in particular.
Before explaining the problem of the palimpsest, we need to trace a bit of the history of the development of the search engine algorithm and discuss certain technical aspects. Without this, understanding the problem will be practically impossible.
3 Stages of Google Search Engine Operation
To understand how the largest collective memory resource we now call the Google search engine is built and functions, I refer to the description on the creators’ website:
Google Search works in three stages, and not all pages make it through each stage:
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers.
Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
Serving search results: When a user searches on Google, Google returns information that’s relevant to the user’s query.
In-depth guide to how Google Search works | Documentation | Google for Developers
How is a Google Search Result Generated?
Below, I present the general principles and elements that construct the generation of a search result, what is taken into account when generating a search result by the Google algorithm. The search result is known as SERP (search engine result page), and the algorithm itself is a set of procedures that deliver information to the SERP and decide on the value and manner of display. It’s worth adding that the algorithm itself is Google’s most closely guarded secret, and the components described below are based on publicly available information.
Crawlers that scan pages and content published on the Internet are divided into discovery and refresh/monitoring - these programs are also known as indexing robots. They analyze the content, structure of the page, and deliver the analyzed information to data centers. To ensure the best analyses, robots scan pages from various locations, and the content of the index is later determined and synchronized between DataCenters (the difference in results depending on the DataCenter is the effect of Google Dancing). It’s the robots and their frequent visits that monitor whether there’s a breach on the site, whether there’s spam, or whether the content has changed to something non-compliant with the regulations. If a robot doesn’t encounter content, the algorithm receives a signal that something is wrong.
CONTENT QUALITY - for Google, the searcher is the Client, so it analyzes the content and quality of the scanned information on the page to match it as closely as possible to what the Client is searching for in the query. Analyzing the content of a page checks its citation reputation, linking, and undergoes anti-spam analysis to ensure we’re not dealing with duplicate content or synonymized text generated automatically - this is to prevent manipulations of accuracy and reliability of information access.
CONTENT ACCURACY - this involves analyzing keywords, i.e., a more detailed semantic matching process to the accuracy of QUESTION <> POTENTIAL ANSWER. Not only the textual layer is analyzed but also anonymous data from page usage, which is converted into signals.
QUERY SIGNIFICANCE - (ranking result) determining what information is being sought - language models establish semantics and decide on the segment of the most relevant content and the language in which the search should be conducted. The ranking of popularity, as obvious, promotes newer and more popular results over time while lowering the reputation of older ones.
CONTENT USEFULNESS verifies the quality of the page, technical execution, presentation style, typography, and adaptation to the device’s screen.
CONTEXT AND SETTINGS here, parameters specific to a particular user are taken into account, such as cookies, location, and personalization of results based on history, as well as the type and settings of the device.
źródło: How search works - Google Search
However, the above 5 elements are just a general outline because the knowledge graph is key in generating and indexing search results in the context of a semantic network (connections of meanings) and integration. This will be particularly important, as in the chapter Algorithm as a Continuous Process, I will show how the knowledge graph is utilized in this context. Meanings are realized on a holistic level, rather than through the analysis of individual elements. Let’s now return to the subject of semantics.
 Illustration: semantic network A semantic network approach to measuring sentiment | Quality & Quantity (springer.com)
Illustration: semantic network A semantic network approach to measuring sentiment | Quality & Quantity (springer.com)
Semantic Network and Knowledge Graph - interprets a user’s query in the context of its meaning, rather than just keywords. This allows for what are known as rich results, or more accurate results. Interestingly, the philosophy behind this was introduced around 2012, marking a turning point in the history of search engines (note this, dear Reader!), but only AI allowed for the true refinement of the algorithm. Such a semantic network enables the creation of connections between signs, objects, and meanings (and for over 4 years now, regardless of language). For example, searching for “Leonardo da Vinci” will semantically link the query with information about Leonardo’s works, his life, and his influence on art (e.g., with concepts like “Renaissance”, “painting”, and “artist”). As you can see, this allows for a significant expansion of knowledge through one simple query. If you want to know more about the semantic network: A semantic network approach to measuring sentiment
Structured Data Markup - Importantly, you must use the appropriate structured data markup technology which provides a standard for interpreting and presenting data in the knowledge graph. This creates possible segments / compartments for content, allowing for the tagging of page content and information contained therein so that they are understandable to indexing robots, i.e., search engines. It also allows the algorithm to realize semantic connections.
High Threshold for Index Entry?
So, if you want to be part of this wonderful universe and deliver content to search engine users, i.e., be part of the graph and increase the visibility of the information or knowledge you share, you must adhere to the standard set by schema.org. If you don’t, your information will not be part of the semantic network designed by Google and others. The effects? Often, commercially oriented or ad-inflated sites are promoted because their technical construction is perfectly refined and dominates over technically inferior sites without structured data.
Incorrect application of schema can mislead algorithms and signal exclusion from the index. Interestingly, there is also the effect of dominating sites like Wikipedia, where mass and quality application of schema result in domination in search results, often over better-quality articles, thereby displacing smaller sites that offer unique approaches or contain interesting analyses. I am referring not only to blogs but also to university sites. (Structured data supported by Google Search | Google Search Central | Documentation | Google for Developers)
If you’re interested in the issues of Schema, indexing, and algorithms, I definitely recommend checking out the article: Autonomous schema markups based on intelligent computing for search engine optimization - PMC. It may not be the most recent knowledge, but it’s still relevant and intriguing.
Here’s a signal for my readers, as many conspiracy theories that arise are precisely at this level, i.e., who creates these standards and what companies are part of the consortia… yes, big tech. It’s important to pay attention to the criticism of how standards are created, for example, the fact that the determination of standards is centralized may bear the hallmarks of political domination and manipulation through, for instance, the exclusion of certain information and not creating certain content segments, causing them to disappear.
DeNardis (2009, 2014) and Russell (2011, 2014) detail the governance of internet infrastructure by examining the roles that institutions such as W3C play where information is controlled, manipulated, and eventually commodified by platform companies. […]
Researchers have foregrounded these explicitly political issues related to networked semantics on the web. Waller’s (2016) and Poirier’s (2017, 2019) ethnographic studies examine how infrastructures on the semantic web (e.g., taxonomies, schemas, and ontologies) are built and reveal the power dynamics embedded in their creation and use.
 Semantic Network and Knowledge Graph - The introduction of Google’s Knowledge Graph and the enhancement of search results in SERPs led to a decline in Wikipedia visits in 2013 compared to the previous year. This was because the information was displayed directly in the SERP, and users did not need to delve deeper. Is Google accidentally killing Wikipedia? (dailydot.com)
Semantic Network and Knowledge Graph - The introduction of Google’s Knowledge Graph and the enhancement of search results in SERPs led to a decline in Wikipedia visits in 2013 compared to the previous year. This was because the information was displayed directly in the SERP, and users did not need to delve deeper. Is Google accidentally killing Wikipedia? (dailydot.com)
Algorithm as a Continuous Process (BERT/MUM)
An interesting modification of the algorithm can be seen during the COVID-19 pandemic, when in 2020, user behavior changed due to lockdowns, many businesses closed, but there was also a sudden increase in mobile device use and online sales. All this necessitated changes and corrections to the algorithm, which had to reflect the pandemic situation.
In 2021, there were about 9.5 changes to the Google algorithm per day in production, totaling approximately 3467 changes for the year, while in 2022, there were 4725 changes in production (12 per day) [source Google Dev]. We see a rapid development of the search engine in recent years. For comparison, in 2009, there were between 350-400 corrections. This means that analyzing search results, we cannot discern a pattern, as they are less consistent and predictable over time, due to the great development of the algorithm and numerous small changes/corrections. This does not mean that the information provided is not accurate and useful. For SEO spammers, this is a nightmare, as it means a permanent adaptive process to changes and finding niches in content pumping. But the problem is not only for SEO spammers but also for companies and content that is massively excluded and whose reputation is lowered, while the rules for creating SERP results are becoming less clear.
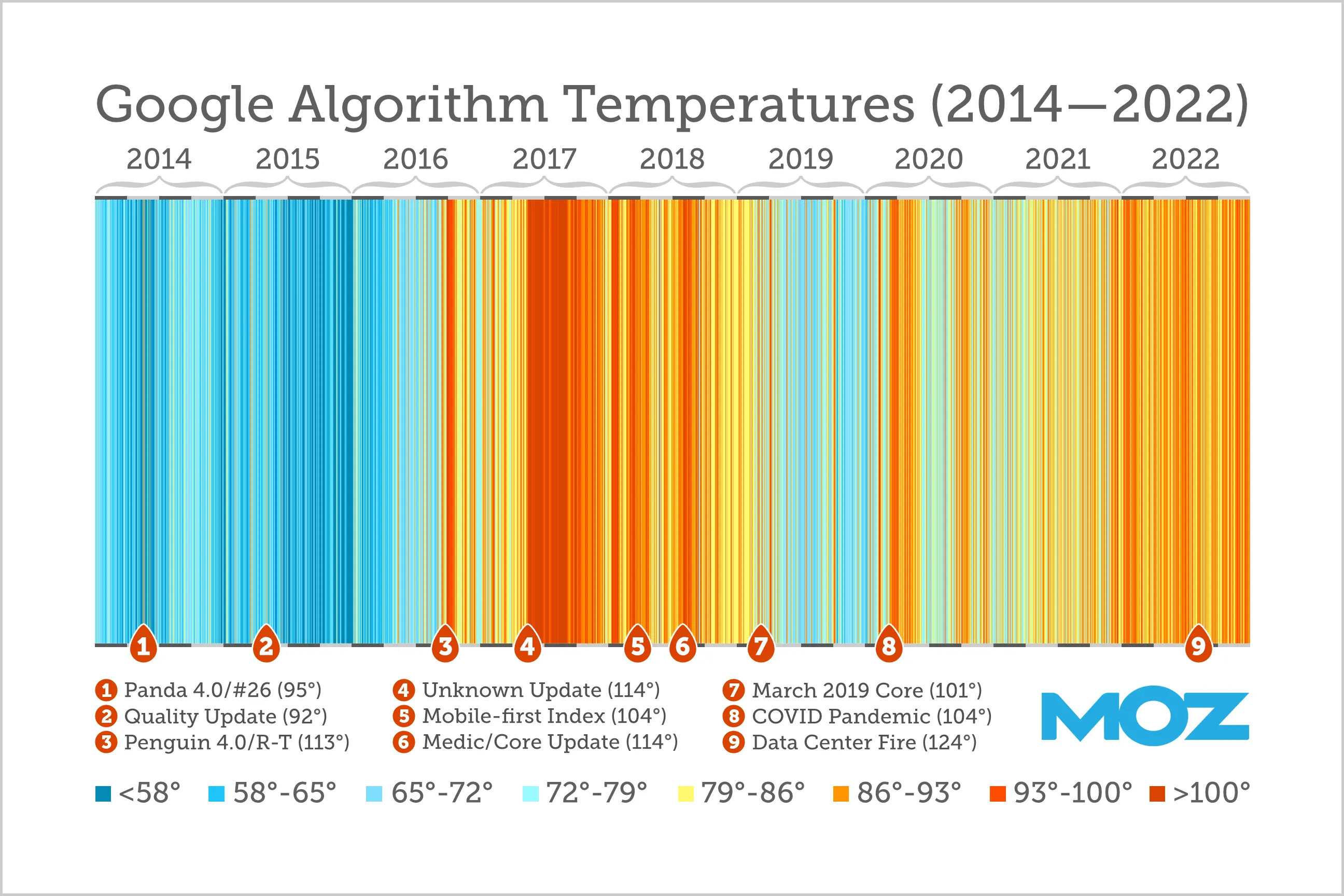 Illustration from the article 9 Years of the Google Algorithm - Moz
Illustration from the article 9 Years of the Google Algorithm - Moz
The use of artificial intelligence has significantly improved the understanding of what can be described as the intentions and motivations behind a specific search. This means that, thanks to AI, specifically advanced models BERT (Bidirectional Encoder Representations from Transformers) and MUM (Multitask Unified Model), we have the possibility of better semantic analysis of information in the context of natural language. BERT allows for understanding the whole sentence without analyzing individual words. MUM, on the other hand, is a step further, processing not only language at the BERT level, but also semantic analysis in many languages and other formats of media, such as images, and most importantly, analyzing them simultaneously on multiple levels.
To sum up, BERT taught Google a better understanding of language, while MUM uses this lesson to understand not just words, but also context, intentions, and complex queries on a completely new level. I find it hard to find a metaphor or analogy that would show the difference and rapid development of this technology. Without delving into technical details, Google has the capability of perfect prediction based on behavioral data, profiling, and segmenting what the user is looking for and probably why, although Google ensures that it does not profile racially, politically, or sexually…
Exclusion from the Index vs. Continuous Adaptation to Changes
I hope I have shown that the Google algorithm is a process subjected to continuous improvements. Therefore, to ensure the visibility of your website on the Internet and avoid its marginalization or disappearance, it is essential to understand that strategies effective today may not yield results tomorrow. This requires competence and continuous monitoring of changes to adjust and correct the structure, presentation form, and respond to potential issues. Based on my experience, optimized pages that comply with current trends and contain valuable content can maintain their visibility in search results for some time. What does this mean? You need to be prepared for costs or devote time to monitoring algorithm changes and communications from Search Central.
Content selection is overseen by an AI and machine learning system called SpamBrain. In 2019, Google detected 25 billion spam pages per day, and in 2022, Google systems detected about 40 billion spam pages daily. This is done automatically, but also by a team that implements manual actions (penalties) and marks pages by lowering their reputation or excluding them from the index. Often, such marking results from, for example, a website breach and modification that displays millions of links to pharmaceuticals in the content (A year in search spam – a report on web spam in 2018 | Google Search Central Blog | Google for Developers). In 2018, Google sent over 180 million messages to site owners about spam issues. Lack of response to critical errors usually means exclusion from the index or such a reduction in reputation that no one will find your content. In the search results, there is also a warning that a site is dangerous for the user and discourages entry. This also applies to the lack of HTTPS or a faulty certificate.
An interesting situation occurred in August 2019 when Google, due to a lack of resources for processing new links and unifying the index status (known as google dancing) between data centers, experienced a failure, which interrupted indexing and damaged the index. Indexing problems: how we solved them in Google search and what we learned | Google Search Central Blog | Google for Developers I won’t discuss this in detail, but it’s worth paying attention to this aspect, as it indicates that, for now, server infrastructure and algorithms created by engineers are implemented through human planning and decisions, often motivated by financial results, constrained by calendars (weekends and fewer human resources), and like all human creations, they can be prone to errors. Therefore, in both algorithms and infrastructure, continuous improvements and corrections are made, and one could say that it is a process subjected to ongoing modifications.
Lowering Reputation and Hiding Information
There is, of course, a downside to this solution in that when searching for information, the algorithm may not accurately predict our motivations and intentions, even if it adopts a paranoid stance that breaks the pattern and safeguards designed by engineers. I use ‘paranoid’ because when building a Model Reader, if it goes beyond the algorithm’s schema, it becomes a paranoid semantics (inconsistent with the assumed meanings). BERT/MUM technology also allows Google to supposedly combat disinformation and fake news, which is rather disputed by researchers - see the excellent article How do search engine users fall down the rabbit hole? (demagog.org.pl). The problem is that fact-checking organizations fighting disinformation and conspiracy theories have full transparency of operation and present their methodology and information analysis process. However, the process of presenting information in Google’s SERP is secretive. The question is, how much will Google exclude, hide, lower the reputation of information based on political decisions or geopolitical interests? Of course, the most famous case is Google’s presence in China and the censorship of search results from 2006-2009 wikipedia.
Without transparency in the operation of algorithms delivering information, it’s easy for such a process of generating collective memory in the form of SERP to be criticized by conspiracy theorists accusing abuses and censorship. Google, as a publicly traded company, is a private entity with shareholders influencing its development strategy.
Summary
In a world of truth decay and universal distrust of all public institutions, universities have a special role to play, not only as a credible source of reliable information and a safe space for substantive debate, but also as a pulpit from which words of truth will flow - straight into the eyes of a power unchecked. (Loc 4452) - Ronald J. Deibert The Great Surveillance. (quote translated from polish edition)
Today’s article contained many complex issues related to the Google index and may not be accessible to everyone. Unfortunately, I couldn’t skip this and decided that it’s impossible to present the disappearance without showing the mechanisms and development of indexing as a technology. I hope I pointed out certain problem vectors and technical description that will help you understand the seriousness of the issue. We live in a digital world where reading a digital palimpsest imposes an interpretation while simultaneously hiding or highlighting certain information. This leads to the formation of conspiracy theories, falling into rabbit holes as described by Demagog.org.pl. I hope my article contributes to the development of not only mechanisms for delivering and circulating information but also reflection on how the rapid development of AI in predicting human intentions and delivering a system of meanings will impact our world.
At the same time, I signal that I cut out entire chapters on digital death, social networks, and statistics with the bounce rate parameter, which are very interesting topics, but due to their volume, they are suitable for a separate article. Whole chapters dedicated to presentations of projects trying to preserve the resource of collective digital memory and digital heritage with nuances related to technical issues, problems, licensing I also decided to potentially pull out for a third article.
Selected sources
Google Search Status Dashboard
Moz - Google Algorithm Update History
Wykrywanie spamu – jak działa wyszukiwarka Google
9 Years of the Google Algorithm - Moz
Open is not forever: A study of vanished open access journals (arxiv.org)
More than 100 scientific journals have disappeared from the Internet
Let’s talk about digital death | Request PDF (researchgate.net)
Open is not forever: A study of vanished open access journals (arxiv.org)
Google’s fact-checking bots build vast knowledge bank | New Scientist Semantic Network - Wikipedia


