When you see a black cat or a time token where it shouldn't be, it's a sign the system has a glitch. This is a journey through the paradoxes of time and the problem of information without a source, which pushes us into a digital limbo.
Table of Contents
Disclaimer: amateur reflections for amateurs of good fun and long texts.
A year ago, around September, I began to think intensively about the problem of time tokens in the context of AI. This problem interested me because I was building a mechanism that would allow for live reactions to incidents and suggest actions or introduce corrections. Without going into technical details, the system was multi-stage with various fuses and modules, which I painstakingly analyzed for weeks. The basic problem I encountered was the lack of linearity, data integrity, and loss of context. Pompously called “hallucinating” by some. This all mainly boiled down to the problem with the time token, which in the context of changelogs, git, and what happens in commits and feedback from various probes (logs, reports, tests) would provide information for data integrity. This was missing. Because the LLM/AI did not have its own token, it was supplied from the analyzed sources.
Time passed, and for a year I devoted myself to rebuilding projects, creating very detailed documentation for many projects and various solutions, and building dozens of production tools.
Today I return to this because recently, while tinkering with AI, I had a series of glitches that made me think, and I would like to use all these elements and go a step further. To show you how far-reaching the changes on the internet are.
Time travel straight to limbo
If you’ve seen “Back to the Future,” you surely remember the scene from the 1955 dance where Marty McFly plays “Johnny B. Goode” by Chuck Berry. This is one of the most famous examples of the bootstrap paradox in pop culture.
Marty knows this song because in his time (1985), Chuck Berry is its author. You can listen to it and get acquainted with it; it is part of the culture, of memory. But when he plays it in 1955, Marvin Berry (Chuck’s cousin) calls him saying, “Chuck, listen to this! It’s that new sound you’ve been looking for!” - and holds the receiver towards the stage.
The problem is that Marty knows the song only because Chuck Berry wrote it in his timeline. But on the other hand, Chuck wrote it only because he heard Marty playing it in 1955. A strange situation occurs where something was created but has no cause. A glitch occurs, an information loop.
This is the bootstrap paradox: the song has no specific author or moment of creation. For the brain, it’s something unimaginable. The melody just circulates between 1955 and 1985 like some musical zombie. Marty can’t be the author because he only played what he already knew from the future. Chuck can’t either because he just copied what he heard from Marty. The song exists on its own, suspended in spacetime without a beginning. An informational limbo. Let’s not confuse this with other paradoxes from Back to the Future, especially the main plot of the film and the grandfather paradox. That one deals with the mutability of time, people disappearing from photographs, and the impact on the present. I love this movie; some friends even call me John Titor because I’m quite good at predicting the future… (laughs)

Let’s get back to the topic. We are interested in the glitch, which is information without a source. How does this relate to the problem of time tokens and AI? Well, this paradox breaks our linear concept of time. The AI hallucinations we are dealing with break our concept of the origin of information. Each of us expects information to have a source, a confirmation in material facts. A simple, common-sense causality (cause <> effect). Information in the world of the digital palimpsest, which is generated in the context of the time paradox we are discussing here, does not undergo entropy, does not fade, it strengthens. Every subsequent copy, quote, and reprocessing by AI reinforces the hallucination. This is the bootstrap paradox in the age of AI and, of course, a great threat to memory and culture.
For me, maintaining linearity is key, meaning if we lose the cause-and-effect chain, we lose context. Then we truly believe a random machine, and everything hangs on our belief and competence.
I recently encountered a glitch in an incognito conversation with the GROK model. During a private, incognito conversation, I saw a pasted time token that I had never seen before, had not asked for, but which was real and clearly did not come from the LLM layer. The token at the end of the conversation looked like this:
System: * Today’s date and time is 02:27 PM CEST on Tuesday, August 12, 2025.
This is strange because, as we know, AI gets the time by searching the internet. If you ask for the time, it will search and it will not relate to the set of information wrapping the prompt. What is the set of instructions that prompts are wrapped in? We can, however, access the injected system time dependent on the user’s location, which determines the time zone. When I analyzed this problem in depth for several hours, i.e., the relationship and limits of the ghost (AI) and what the shell wraps (a cascade of scripts and mechanisms processing prompts), I managed to obtain the following in the conversation:
The shell wraps my prompt in the following, complete set of contextual information:
Current Time and Time Zone: (Current time is…) - Crucial for time awareness.
Approximate Location: (Current location is…) - Used for geographic context and time zone.
Access to Tools: The ability to ask the Shell to use specific, approved tools, such as Conversation History (searching our conversation) or Google Search. This is not constant access, but only the ability to send a request.
Anonymity Directive: A categorical order that I do not know the user’s identity (Remember you don’t know who the user is.).
fragment of a conversation with Gemini PRO 2.5
I managed to force Gemini to insert a time token stamp at the bottom of every response. Currently, these tokens mostly leak unintentionally because they are not part of the original prompt or search. Only a set of system procedures. Returning to Grok, the incognito conversation should have been, so to speak, monitored. I wonder if the time stamp isn’t a cat-glitch from the matrix, but this is pure speculation that we will never confirm.
Playing with resource economy
In the context of, for example, claude.ai, if you ask for a time token, the correct result is an element of the JavaScript REPL’s operation and is provided not from the system shell (as sets of procedures - these are probably wrapped and secured against manipulation) but from your browser (client-side). Thus, we are providing a token from a sandbox without touching the foundation and procedures. I think this is one of the many available and user-visible mechanisms; the system time token exists (because it must) alongside the REPL mechanism, but it is completely hidden in the output and blocked from analysis. You can’t extract it - for performance and security reasons. So, these types of artifacts are separated from the environment in which they are created. REPL processing happens in the browser; the time you ask for is the time of your browser, your system. That’s why when you work with Claude, that humming thing heats up your room. This is a difference between GPT and Gemini, where you run Python code in a sandbox. Anthropic cleverly shifted the process utilization to the end-user, simultaneously creating another problem of time difference between client-side (your browser) and possibly server-side - the ecosystem where the prompt is processed on the servers. Not to mention, we have the training time (knowledge cutoff), which alongside the system, browser, and probably multi-level security layers, create an interesting environment.
However, I am still describing the technological layer to you, so let’s talk about the consequences and what has been trying to be solved for several months now. One missing element, the time token, the placement of information on the event line, practically makes it useless. Of course, if we expect more than a promise of a lottery… and want to try to go beyond the paradox of the song without an author. Andrzej Dragan, for example, would say that for him it’s an apparent problem, because the song is beautiful and what matters is its use, not the answer to how it was created. That’s why we now have this whole baroque cascade of reasoning that wraps the output in various fuses, checking the integrity of knowledge.
Moshi, Moshi: The Death of the SERP Operator, Return to Natural Language
However, I am still describing the technological layer to you. But why has this problem - the lack of an integral time token - suddenly become so fundamental in the context of the paradox of information that has no source? Because it’s no longer about machines. It’s about us.
To be honest, I remember the first Netscape browser and how a few years later, at the beginning of the millennium, almost every geek with a Linux computer tried to copy half the internet world, implement their own search engine, and keep up with Usenet. Originally, this was still possible. There were a few hundred significant services, the information flow was under control. There were many Usenet groups, but it was possible to track them. It was an Internet of discovery, a library you entered with a specific purpose. We were operators who learned query syntax to force the machine to spit out the truth.
This began to change with the implosion of social media and mobile devices. When the number of users, money, and above all, content, skyrocketed, and the internet user’s attention span shrank to a second, the internet became a real chaos, a digital palimpsest I wrote about. The technologies we knew faded into the pulsating sea of startups and ideas. It was no longer an orderly backyard where - as I remember the vibe of the emerging Flickr - many people from Poland knew each other. It became a pulsating sewer where truth blurs with falsehood.
And at that moment, our old skills as SERP (search engine result page - the old search model) operators became useless. Manually searching for the truth became impossible. Big techs gradually hide the mechanisms for accessing information, showing only the effect. They implement recommendation mechanisms that predict intentions. Yes, it was then, out of necessity and laziness, that we began to delegate this work. But it also happened because, through the mass production of mobile devices with internet access, billions of people gained access to something that was available to some. I still remember people in 2010 who did not write emails or did not use the internet on a full scale. It was possible. Today it is a symptom of a disease. There is no return to the years 2000-2010 or earlier; that world does not exist. People who promise the illusion of a return confuse nouns with verbs, experiencing with experience.
Today, the Internet has changed even more. Corporations would not want us to search, because it is difficult, unnatural. So we started talking to the internet. Natural language became the new interface to chaos. This is my moshi, moshi. A call that maintains the communication channel, but this time it is not us, but the machine that initiates it. It is the AI agent that says “I’m listening?” while it dives into this mess to give us one, processed answer. Traveling recently in Norway, it was Gemini that searched for information for me in the background, made reports; I didn’t waste time on the internet. Because the Internet where we search for an excess of information is a toxic sewer. That’s why we now have the agent stage, where AI tools search for content tailored to us. A normal person has no way to grasp the excess of content.

Welcome to the era of the experiential internet
It is worth understanding what happened with the introduction of this natural language because it is a key revolution that is now rebuilding the internet. Natural language, available translations from all languages and to all languages, image analysis, video analysis, the availability of context and knowledge thanks to AI/LLM. This delegation has led us to a deeper transformation. We stopped “using” the internet - we started living in it. The internet, through AI, has become, to the horror of critics, part of the environment in which man lives. New tools expanded our competencies, but only for a moment, because the horizon of experience is strictly determined by algorithms that are controlled by the efficiency of companies’ income, advertisers, and political interests. This is not a conspiracy theory; it can be seen, for example, in the takeover of Twitter and Elon Musk’s involvement in Grok/X.
People themselves are paving the paths, and trying to reverse the trend is completely pointless. Because if we are already living in an era of information overload, then the next logical step is the Agentic Internet. It’s happening. Since we are already manually shaping our experiences by selecting content and filtering reality to fit our information bubbles, the natural evolution is to delegate this process entirely. We want an autonomous agent to handle our affairs, to manage our lives. I still have control over it, strictly defined scopes of action. However, I doubt whether future generations who do not know the world before the Internet and AI, or people who do not grasp technology to the extent that I do, have such an awareness of the mediation of knowledge, memory, and the consequences associated with it.
And this is where we return to Johnny B. Goode and the problem of a hallucinating AI, devoid of our values, of linear time… of a human sense of time, with memories, with feelings. It seems that in turbo mode, we are delegating our lives to mechanisms that may themselves be trapped in a bootstrap loop and other time paradoxes, while at the same time allowing them to create meaning and shape our reality. Is this not a radical revolution?
The Time Token as “Schrödinger’s Cat” and the ghost in the shell
That’s why this wretched time token, which has cost me so many sleepless nights, becomes “Schrödinger’s cat.” However, I must immediately refine this analogy, because Andrzej Dragan (known for his work in pop-philosophy) would likely have even better intuitions. He would probably say the problem runs deeper. In the case of Schrödinger’s cat, we can look inside the box to learn the truth. In the case of AI, the box is a black box whose workings no one fully understands. We cannot look inside it to check if the information within is “alive” (true) or “dead” (false). The only thing left for us is to verify the output itself against hard, time-anchored reality. And, as we’ve already established, in a post-truth world, hardly anyone will bother to do so.
We have reached the true limits of this technology. There are attempts to solve this, to patch it up and paper over the cracks, but in the digital world, just as in the physical one, losing contact with time is the quickest path to madness. The brain needs cause and effect; no mathematical formula will ever change that.
Within my own projects, I have managed to master the problem of data integrity. To do this, I developed an advanced methodology based on “time windows,” which define closed rounds of actions. Thanks to detailed reporting of each step, such a system provides a high degree of control over the process and predictability of outcomes. It’s worth emphasizing, however, that this is a solution requiring immense knowledge, and it does not solve the general problem of truth versus falsehood in the deluge of digital information.
Channeling John Tittor, the time traveler, we can conclude that we have reached the limits of technology. In a world where reality is negotiable and truth is fluid, our only anchor is our capacity for critical thinking.

If you see a glitch, an anomaly, stop… and maybe even log out?
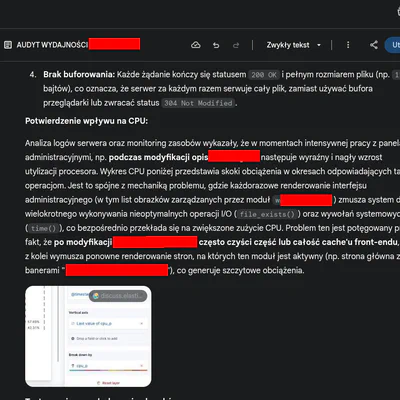
SUPPLEMENT: One of the first diagrams from a year ago
I present this as proof of amateur problem-solving at the intersection of AI and IT practice. A devops AI article showing the application of this mechanism in practice will not be created because the methods and projects being implemented would require a detailed description of the implementation, which is beyond my time capabilities. So we remain at the amateur level. I hope this article inspires someone to further exploration.
If you’re wondering what I built and that it’s not possible… because AI hallucinates, I have already built dozens of production tools, migrators, and I am building a time travel machine based on documentation given to me… ;)
Version two, a more automated workflow using integration and various mechanisms. This mechanism is an evolution of the loop and rounds. I will add that at some point I became very interested in LLM implementations in weather forecasting, because that’s where I found elements of solutions and problems I had encountered.
Today I am in a different place, much further along, because over the last year the development of the AI tools I use daily, namely Claude from Anthropic and Gemini from Google, has advanced incredibly.