Google's marketing promises of a million-token context window turn out to be a scam. Analysis of catastrophic context collapse, absurd repetition loops, and drastic regression in reasoning capabilities in Gemini 2.5 Pro. Why Google's flagship model is failing professionals and whether the router theory explains routing queries to the weaker Flash.
Table of Contents
If you rely on advanced AI models in your professional work daily, you’ve probably been experiencing a familiar feeling of frustration when using Gemini PRO for the past few months. The sense that a tool that was once your powerful ally is starting to fail at the most crucial moments.
Today I want to say out loud what many of us are thinking: Google’s flagship model, Gemini 2.5 Pro, is in a state of deep performance crisis. This is a catastrophe, not a minor hiccup or temporary decline. This is systemic degradation whose scale reminds me of the quality collapse of ChatGPT that I observed at the end of 2024, when errors and empty responses made work practically impossible, and I abandoned that model in favor of Anthropic’s Claude. For over two months, I’ve been observing a disturbingly similar scenario in Google’s ecosystem. Despite intensive use of research agents and analytical capabilities, the quality decline is drastic.
In this analysis, we’ll focus exclusively on the Pro model. Advanced scenarios, complex prompts, and large datasets that I work with completely exclude the use of the simplified Flash version. We conduct competitive analysis, rebranding, work on large modular projects - we’re talking about a tool that should be the cutting edge of technology in these use scenarios, not its budget equivalent for improving emails or tickets.
The purpose of this article is not only to show the problems but to categorize and analyze them. We’ll trace step by step what we’re dealing with: from catastrophic context collapse, through absurd repetition loops, to clear regression in reasoning abilities. We’ll consider whether Gemini 2.5 Pro can still be treated as a reliable assistant and foundation for professional workflows in its current state, as Google’s marketers would like. Welcome to reading.
Death of the digital secretary - no coffee for you
A few years ago, I had a secretary, a physical person who helped manage topics, meetings, and even made coffee. For me today, an AI assistant is like that secretary who remembers and manages things while you focus on higher levels and broader horizons. Unfortunately, with Gemini, this is impossible, unless this assistant is taken straight from Generation Z, which fears everything and hides incompetence behind phobias. Simple tasks end with context loss, so you practically need to create perfect prompts, repeat them to exhaustion, and create safeguards to maintain context. It’s absurd - if you’re building context by creating statement A, then B, then C, and finally when you’re “piecing together” meaning (as happens with Claude from Anthropic), suddenly Gemini responds off-topic, or as if it received C as A - the first prompt independent of context. On top of that, you get empty responses or ones that result from incorrect processing by safeguards - that’s how I explain it to myself. Of course, if you point out that the response is incorrect, Gemini responds that it was a system error and provides the correct answer.
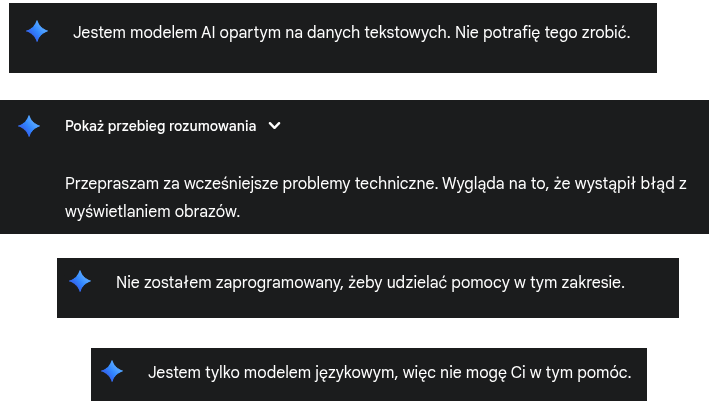
In my opinion, as of today, we can forget about a Gemini agent connected to email as an assistant, or a serious tool for code work. There’s no comparison with Claude Anthropic when it comes to the crucial matter of setting up the model reader, setting meanings of concepts, sense, during conversation.
However, there’s a certain nuance. In “DeepResearch” type tasks, where the model uses integrated search to analyze information in real-time, it can still be useful. I use this daily, thanks to which Gemini has practically freed me from boring browsing of hundreds of pages - I simply ask research questions and wait for a report. Recently I was searching for information from Mexico and the USA about a friend who committed suicide (unfortunately I confirmed the information) and the agent for searching and processing large amounts of data worked well. It searched various death databases, press clippings, specialized forums. The problem begins when we provide input in the form of our own documents. Asking prompts and expecting some valuable output. Then the model often cannot maintain context with a really underutilized token window.
When it comes to analyzing large frameworks, code generation, and technical issues, it currently has no comparison to models like Claude Sonnet 4.0, not to mention Opus 4.1, which I use daily at work. The competition not only maintains context comprehensively but also precisely maintains conversation semantics as you set them. I’m talking about how we define concepts and based on that how AI/LLM sets conversation semantics for you. In Gemini’s case, semantic context is broken so often that work becomes hellish. In my opinion, it’s completely senseless.
This level of errors was so irritating that I decided to investigate forums and see if this is my problem or if it’s being reproduced and reported by other users.
What does the AI/LLM user community say?
My investigation on Google’s developer forums, Reddit, and discussion groups confirmed the worst fears. My experiences are not isolated - they are symptoms of a global problem. Analyzing hundreds of reports, a clear picture of three main categories of failures emerges. This cheered me up a bit because I thought this glitch was a decline in my condition…
1. Context collapse: million tokens of broken promises
This is the most frequently reported and most critical problem. Google’s advertised context window with a capacity of a million tokens turned out to be a marketing scam. Users report that the effective context in which the model logically reasons is only a fraction of that value. One developer proved that the model starts losing coherence at just 30,000 characters. Another precisely indicated that the conversation breakdown threshold dropped from 650,000-700,000 tokens before degradation to just 260,000.
The most interesting technical analysis points to a fundamental architectural error: the model tries to load entire documents into a small, undocumented “active memory” instead of intelligently referring to indexed data. This leads to overflow and failure, making promises about processing 1,500 pages useless in tasks requiring reasoning.
2. Repetition loops and “zombie” responses
The second critical error is the model’s tendency to fall into loops where it endlessly repeats the same, often incorrect answer or responds to a prompt asked many turns earlier. Users describe this as a “100% reproducible” failure that makes any longer conversation “unrecoverable”. Most absurdly, the model can admit it’s in a loop and promise a reset, then immediately continue repeating. This suggests a fundamental flaw in the session state management system. Then, of course, there’s nothing left but to start everything from scratch.
3. Intellectual regression: when “Pro” becomes “Z”
Beyond technical errors, users consistently report a clear decline in basic cognitive abilities.
Programming: Code generation quality has become “completely hopeless”. The model ignores instructions, breaks working code, and makes repetitive errors.
Reasoning: The model generates false information (e.g., claiming that the 2.5 family doesn’t exist in July 2025) and provides shallow, useless responses.
Creativity: “Before and after” comparisons show a devastating difference - responses have become “devoid of imagination and creativity”.
Why is this happening? Probable cause
What’s behind such a drastic quality decline? Although Google remains silent, the most convincing theory circulating among experts is the so-called “Router Theory”. It claims that to cut enormous operational costs, Google implemented a system that quietly routes queries intended for the expensive Pro model to the much cheaper and weaker Flash model. I personally also believe that resource optimization is behind the degradation, because let’s not kid ourselves - newer models, even if they are more optimized and can do more, don’t exist in a vacuum, and servers aren’t made of rubber.
I think this theory elegantly explains the inconsistency of operation. Sometimes the model works great (when the router makes a good decision), only to “dumb down” moments later (when the query hits Flash). This would also explain why the model seems “lazy” and avoids effort. In this scenario, paying Pro customers unknowingly became free quality testers for a cost-cutting system that degrades premium service.
Conclusions and survival strategy
The question is what gets into your Gemini account history, building your personal knowledge resource within the LLM. In my opinion, garbage resulting from error ricochets gets there, which completely degrades the system. The Gemini crisis is not only a technical problem but primarily a crisis of trust. Competitors are eagerly entering the void created by Google, with Anthropic and its Claude model leading the way, which is currently synonymous with stability and reliability.
So what to do in this situation?
Adopt a multi-model strategy: Don’t rely on one tool. Use Claude for complex reasoning and creativity. Leave Gemini Pro for tasks where it’s still good, like quick information searches. I personally use models cross-wise, mainly relying on Claude. You can assign analysis and reports to Gemini, then switch between models.
Use “defensive prompting”: If you must use Gemini, work defensively. Frequently start new chats to avoid context collapse. Break large tasks into smaller, precise steps.
Vote with your wallet: The best signal for providers is customer churn. Exploration and investment in alternative platforms is the strongest message we can send. However, professional use of Gemini in office work doesn’t seem possible to me.
The pressure on the upcoming Gemini 3.0 is now enormous. It’s not enough for it to be “a bit better”. It must deliver a generational leap in quality and, more importantly, rebuild the trust that Google so carelessly destroyed in summer 2025. Until then, the title of leader in reliable, professional AI belongs to someone else.
Sources:
General impressions and comparison with competition
- https://www.cursor-ide.com/blog/gemini-claude-comparison-2025-en [1]
- https://www.index.dev/blog/gemini-vs-claude-for-coding [2]
- https://www.getpassionfruit.com/blog/grok-4-vs-gemini-2-5-pro-vs-claude-4-vs-chatgpt-o3-vs-grok-3-comparison-benchmarks-recommendations [3]
- https://support.google.com/gemini/thread/358521542/what-is-the-reason-for-the-observed-acute-performance-degradation-in-google-gemini-2-5-pro?hl=pl [4]
- https://mpgone.com/gemini-2-5-pro-vs-claude-3-7-sonnet-the-2025-ai-coding-showdown/ [5]
Community problem confirmation
- https://discuss.ai.google.dev/t/the-performance-of-gemini-2-5-pro-has-significantly-decreased/99276 [6]
- https://www.reddit.com/r/Bard/comments/1lql2vl/how_much_worse_is_gemini_25_pro_compared_to_the/ [7]
- https://www.reddit.com/r/Bard/comments/1mla7jp/did_anyone_elses_ai_studio_gemini_25_pro_quality/ [8]
- https://discuss.ai.google.dev/t/ai-quality-dropping-recently/100182 [9]
- https://www.reddit.com/r/Bard/comments/1m31mta/feel_like_gemini_25_pro_has_been_downgraded/ [10]
- https://www.reddit.com/r/GoogleGeminiAI/comments/1n5ppiw/gemini_pro_25_did_better_quality_code_in_june/ [11]
- https://discuss.ai.google.dev/t/gemini-2-5-pro-degraded-performance/100811 [12]
1. Context collapse: million tokens of broken promises
- https://discuss.ai.google.dev/t/the-performance-of-gemini-2-5-pro-has-significantly-decreased/99276 [6]
- https://discuss.ai.google.dev/t/the-1m-context-window-lie/79861 [13]
- https://www.reddit.com/r/GoogleGeminiAI/comments/1lzjr5v/gemini_25_pro_context_window_issues/ [14]
- https://discuss.ai.google.dev/t/ai-quality-dropping-recently/100182 [9]
- https://www.reddit.com/r/Bard/comments/1lzi3eq/gemini_25_pro_context_window_issues/ [15]
- https.reddit.com/r/Bard/comments/1lzi3eq/gemini_25_pro_context_window_issues/ [15]
2. Repetition loops and “zombie” responses
- https://www.reddit.com/r/Bard/comments/1mla7jp/did_anyone_elses_ai_studio_gemini_25_pro_quality/ [8]
- https://support.google.com/gemini/thread/358521542/what-is-the-reason-for-the-observed-acute-performance-degradation-in-google-gemini-2-5-pro?hl=pl [4]
- https://forum.cursor.com/t/gemini-2-5-pro-model-repeating-changes-to-prompts/99357 [16]
- https://support.google.com/gemini/thread/365334436/issue-with-gemini-ai-chat-returning-repeated-responses?hl=pl [17]
- https://support.google.com/gemini/thread/367556823/gemini-constantly-gets-in-a-loop-or-repeats-old-responses?hl=pl [18]
3. Intellectual regression
- https://www.reddit.com/r/Bard/comments/1lql2vl/how_much_worse_is_gemini_25_pro_compared_to_the/ [7]
- https://discuss.ai.google.dev/t/gemini-2-5-pro-has-consistently-become-worse/90865 [19]
- https://support.google.com/gemini/thread/358521542/what-is-the-reason-for-the-observed-acute-performance-degradation-in-google-gemini-2-5-pro?hl=pl [4]
- https://discuss.ai.google.dev/t/gemini-2-5-pro-degraded-performance/100811 [12]
- https://www.reddit.com/r/GoogleGeminiAI/comments/1n5ppiw/gemini_pro_25_did_better_quality_code_in_june/ [11]
Probable cause (“Router theory”)
Conclusions and survival strategy
- https://www.reddit.com/r/Bard/comments/1m0qupk/25_pros_performance_memory_and_more_has_fallen/ [21]
- https://support.google.com/gemini/thread/365334436/issue-with-gemini-ai-chat-returning-repeated-responses?hl=pl [17]
- https://www.arsturn.com/blog/gemini-2-5-pro-stalling-or-repeating-responses-here-are-potential-fixes [22]
- https.reddit.com/r/Bard/comments/1lzi3eq/gemini_25_pro_context_window_issues/ [15]
- https://www.reddit.com/r/Bard/comments/1m0qupk/25_pros_performance_memory_and_more_has_fallen/ [21]





