Biorę na warsztat zagadnienie cyfrowego zanikania treści. Inspirując się koncepcją palimpsestu, analizuję, jak cyfrowe warstwy informacji są sukcesywnie zastępowane i jak ważne treści mogą znikać z naszego cyfrowego świata. Artykuł odkrywa tajniki działania algorytmów Google, rzucając światło na ich wpływ na dostępność i widoczność informacji w sieci.
Spis treści
Nieustające ani na chwilę, zalewające nas w czasie rzeczywistym tsunami informacji stwarza doskonałe warunki dla rozprzestrzeniania się nieprawdziwych opowieści, teorii i spiskowych i przecieków. Wdrukowane błędy poznawcze i skróty myślowe sprzyjają przekazywaniu ich dalej. (Loc 1802) Ronald J. Deibert Wielka inwigilacja.
Do napisania dzisiejszego posta natchnęło mnie przeczytanie kilku książek, o których wspomnę, oraz wysłuchanie wywiadów m.in. z Piotrem Pytlakowskim, który napisał Strefę niepamięci o zanikaniu i wymazywaniu historii polskich żydów. Pamiętam, jak byłem na Bałkanach i spytałem miejscowych o puste place w wiosce albo porzucone niszczejące domy. Odpowiedzieli mi: nie wiemy, oni wyjechali. Oczywiście ci ludzie zostali w większości wymordowani podczas czystek etnicznych wojny w byłej Jugosławii. Cała nasza kultura opiera się na tradycji i pamięci, a to, co jest przemilczane i wyparte, zanika. Patrząc na raptowny skok technologiczny, zmianę przyzwyczajeń w wyszukiwaniu informacji, ale także przekazywaniu informacji, zacząłem się zastanawiać nad zanikaniem w świecie cyfrowym.
W dzisiejszym poście chciałbym omówić problem zanikania różnorodności treści w kontekście algorytmów wyszukiwarek internetowych. Te algorytmy, stając się dla wielu głównym źródłem informacji, prezentują treści w różny sposób. Poprzez dostarczanie określonych znaczeń, algorytmy stają się narzędziami interpretującymi świat. Analizuję tutaj, jak zawarte w nich behawioralne mechanizmy przewidują nasze motywacje oraz jak sieć znaczeń, którą tworzą, realizuje pewną interpretację. Wrzucają nas one do semantycznego wora znaczeń, które mogą nam odpowiadać, ale są one wynikiem działania algorytmu, a nie naszego własnego rozumowania. Kolejnym problemem jakim się zajmę to ukrywanie albo wymazywanie całych połaci informacji z Internetu, co nazywam zanikaniem. To bardzo niebezpieczne i fascynujące zjawisko, któremu przyjrzymy się w kontekście technicznym, mam nadzieje zrozumiałym dla laika. Zapraszam do lektury.
zanikanie informacji w Internecie - przykłady zanikających treści i cyfrowej erozji
Coraz częściej mam problem z wyszukaniem starszych informacji, które widziałem jeszcze 10 lat temu w Internecie. Dotyczy to wydarzeń albo osób sprzed 20 lat z mojego rodzinnego miasta Wrocławia i ku mojemu zdziwieniu nie mogłem ich w ogóle znaleźć. A były to wydarzenia artystyczne, fakty, różne afery albo artykuły naukowe. Znam też blogi z okresu 2005-2008 rok po których nie ma żadnego śladu pomimo, że były bardzo popularne i niektóre zostały wspomniane np. przez ogólnopolskie tygodniki.
Znalazłem raptem kilka dyskusji na reddit gdzie osoby narzekają, że nie mają dostępu do treści blogów oraz, że nikt nie zrobił pełnego zrzutu stron przez co zupełnie zniknęły i brak jest po nich jakichkolwiek śladów… Jak to możliwe? Będziemy dzisiaj zastanawiać się nad formami pamięci zbiorowej i zanikania w kontekście informacji dostarczanych na różnych nośnikach ale także przez Google. Zanim jednak dojdziemy do wyszukiwarek i algorytmów zastanówmy się co to jest erozja cyfrowej pamięci, zanikanie treści ale także intencjonalne przemilczanie faktów w zbiorowej świadomości? Czym to grozi i jakie są potencjalne zagrożenia? Prześledźmy różne sposoby erozji.
erozja cyfrowej pamięci
W dzisiejszym artykule przeanalizujemy ten problem. Każdy z nas natrafił na znikające informacje w Internecie. Informacje mogą zmienić swoją pozycję, mogą też poprzez zmiany w algorytmach z czasem być trudniejsze do wyszukania. Mogą też być z przyczyn technicznych całkowicie usunięte. Omówmy najpierw techniczne powody zanikania informacji z których do najbardziej oczywistych musimy zaliczyć:
wygaszanie domen i w konsekwencji usunięcie z indeksu Google - skoro nie ma domeny to nie tylko nie mamy dostępu do źródła, ale także po pewnym czasie do duplikatu źródła z indeksu Google i treść znika.
usuwanie stron internetowych z prozaicznych przyczyn personalnych, finansowych ale także technicznych np. z powodu braku wsparcia dla oprogramowania i włamania autorzy podejmują decyzję o wyłączeniu projektu. W przypadku analizowanych poniżej znikających czasopism naukowych to właśnie model biznesowy polegający na opłacie za dostęp i nieosiągnięciu pułapu dochodu stał za przyczyną upadku serwisu i zanikania treści. Bądźmy też realistami. IT oraz utrzymanie serwisów to są czasami poważne koszty.
do częstych przyczyn należy także po prostu utrata danych spowodowana ludzkim błędem, atakiem włamywaczy albo uszkodzeniem nośników. Spalenie serwerowni OVH gdzie była produkcja i backupy w tym samym miejscu co pokazało administratorom i twórcom trzymającym tam dane, że chmury są realne i podatne na awarie.
tworząc nową wersję strony nie zapewniamy ciągłości treści i nie migrujemy starych danych do nowej strony, usuwamy treści i nie reindeksujemy poprawnie adresów URL - częściowo Google to sam naprawia poprzez proces reindeksacji, ale jeśli treści nie ma, to nie kieruje swoich klientów na błędne linki i usuwa je z indeksu.
Jeśli nie ma wielu wzmianek w mediach mainstreamowych z cytowaniem, to informacje również zanikają. Tutaj analogia do niepamięci i przemilczania, gdzie historycy mają problem z odtworzeniem faktów ponieważ nie mają źródeł. Jest to zatem jakiś sposób cyfrowego wykluczenia i wymazywania - jeśli nie jesteś cytowany i komentowany, to ciebie nie ma. Algorytm popularności o którym będziemy mówili też odgrywa tutaj rolę analizując popularność.
erozja nośników i danych z serwerów
Wiele osób zainteresowanych prywatnością danych idealizuje przekonanie, że “w Internecie nic nie ginie”. Jednakże, trzeba jasno powiedzieć: feteszyzując trwałość danych, tworzymy mit oparty na nierealistycznym postrzeganiu niezawodności i zaufania do metod przechowywania danych. Jest to stwierdzenie kuriozalne i całkowicie niezgodne z rzeczywistością! Weźmy chociażby pod uwagę rzeczywiste wyzwania związane z kosztami, zarządzaniem danymi, serwerami oraz zmianami własności firm odpowiedzialnych za te dane.
Laik wierzący w taki mit będzie później bardzo zdziwiony gdy np. serwis utrzymujący fotografie usunie wszystkie jego zdjęcia. Tak stało się po przejęciu Flickra przez SmugMug, gdy zmiana w polityce korzystania z serwisu spowodowała usunięcie 63% zdjęć i obrazów utrzymywanych na serwerach. Kapitalizm Inwigilacji daje w zamian za nasze dane możliwość darmowego korzystania z usług, ale też jest to obwarowane regulaminami mówiącymi, że dane nie są bezpieczne w tym sensie, że nie gwarantuje się ich integralności i mogą zniknąć w każdej chwili. I rzeczywiście nie raz zniknęły.
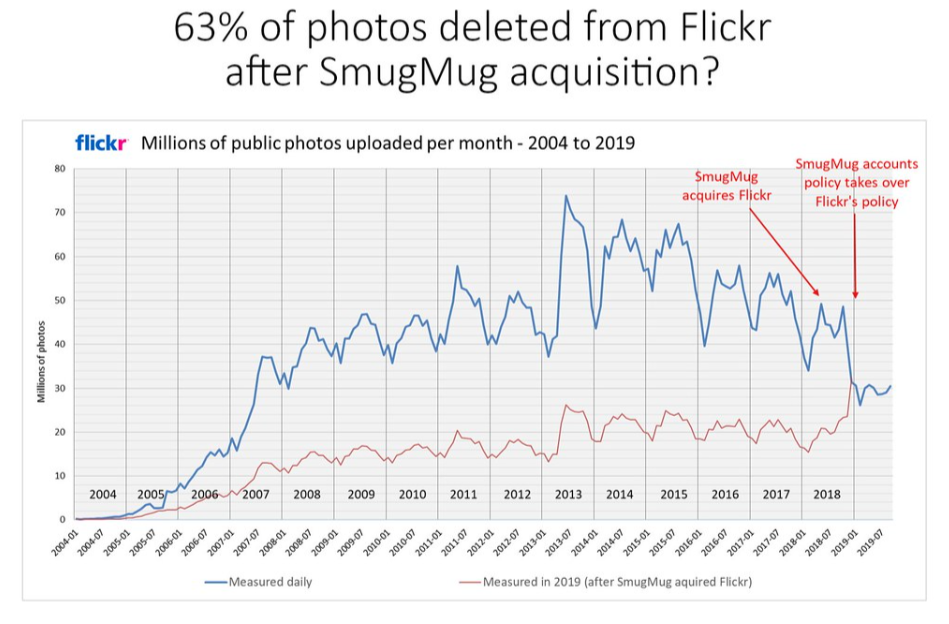
Flickr stoi też za przypadkowym usunięciem zdjęć użytkowników, co zdarzało się wielokrotnie również Googleowi np. poprzez błędne zastosowanie algorytmu kompresji. Pojawiały się też artefakty na starszych zdjęciach - Google jednak wyjaśnił, że spowodowane to było również kompresją. Internet puchnie od historii użytkowników, którzy utracili swoje oryginalne zdjęcia z powodu wadliwych narzędzi do importowania, błędu inżynierów obsługujących centra dane, albo niewłaściwej migracji. Flickr accidentally “permanently” deletes user’s 3,400 photos | Digital Trends oraz UPDATE: Flickr User Says Site Deleted 4,000-Picture Account | PCWorld Don’t migrate Flickr photos to SmugMug » (colinpurrington.com)
erozja multimediów i fizycznych nośników
Problem erozji dotyczy nie tylko informacji umieszczonych na serwerach ale np. filmów, obrazów, multimediów. Jako przykład niech posłużą tutaj znikające filmy i seriale, które z różnych przyczyn zostały nie tyle ukryte co zupełnie wycofane z serwisów streamingowych. Ulegają one zanikaniu, a niekiedy nowa polityczna poprawność albo partykularne interesy udziałowców mogą sprawić, że są wymazywane z katalogu bez możliwości dostępu. Disappearing Content: Media is still getting wiped today | Watch | The Take
Do tego możemy dołożyć wszystkie nośniki fizyczne takie jak stare dyskietki, kasety magnetofonowe, płyty cd, dvd, BluRay itp. Płyty CD są tworzone z warstw polikarbonatu, aluminium, złota, srebra lub innego metalu i lakieru. Z czasem, te warstwy mogą ulegać degradacji chemicznej, często w wyniku utlenianiu, co prowadzi finalnie do utraty danych. W płytach CD-R, gdzie dane są zapisywane za pomocą specjalnego barwnika, który reaguje na światło lasera zmieniając swój kolor, a sam barwnik z czasem też może się rozkładać. Dodatkowo, warstwa reflektywna (najczęściej wykonana z aluminium) może ulec korozji, co również prowadzi do utraty danych. Jeśli właśnie macasz ze łzami swoją kolekcję CD, to nie jesteś sam…(za zwrócenie uwagi na fizyczne nośniki i zanikanie dziękuję użytkownikowi @wikiyu@infosec.exchange z fediwersum)
zanikające publikacje naukowe, blogi i strony instytutów
Na szczęście nie muszę Państwu przedstawiać żmudnej analizy indeksu i dowodzić, że rzeczy znikają ponieważ są już poważne artykuły i dysertacje naukowe traktujące o tym problemie. Z artykułu w Nature opublikowanego w 2020 roku możemy się dowiedzieć, że w ostatnich 20 latach zniknęło z Internetu ponad 174 naukowych czasopism (źródło). Bezpowrotnie! Większość znikających czasopism z analizy była z dziedziny nauk społecznych i humanistycznych (RIP!), ale reprezentowane były również nauki przyrodnicze, nauki medyczne, nauki fizyczne i matematyka. Osiemdziesiąt osiem czasopism było powiązanych z towarzystwem naukowym lub instytutem badawczym. Większość znikających czasopism zniknęła w ciągu 5 lat od momentu, w którym serwisy przestały publikować artykuły. Około jednej trzeciej zniknęło w roku od ostatniej publikacji.
Ktoś mógłby powiedzieć what’s the deal, przecież dobre publikacje zawsze się obronią. Nie do końca można się z tym zgodzić. Wiedza i cytowane źródła nie powinny znikać. Poza tym podobno w Internecie nic nie ginie, prawda? Jak opisałem wcześniej w przyczynach technicznych, to właśnie brak finansowania w modelu opłat za dostęp i niewypracowaniu odpowiedniego poziomu dochodów stał wraz ze wzrostem kosztów IT oraz konkurencją wydawniczą za upadkiem wielu wydawnictw, czy instytutów. Tutaj bardzo ciekawy rykoszet jest też taki, że znikające czasopisma w modelu płatnym padły ofiarą Otwartych Zasobów Naukowych, które są bezpłatne, jest ich coraz więcej i są bardziej atrakcyjne niż zamknięte i płatne zasoby. źródło: Open is not forever: A study of vanished open access journals
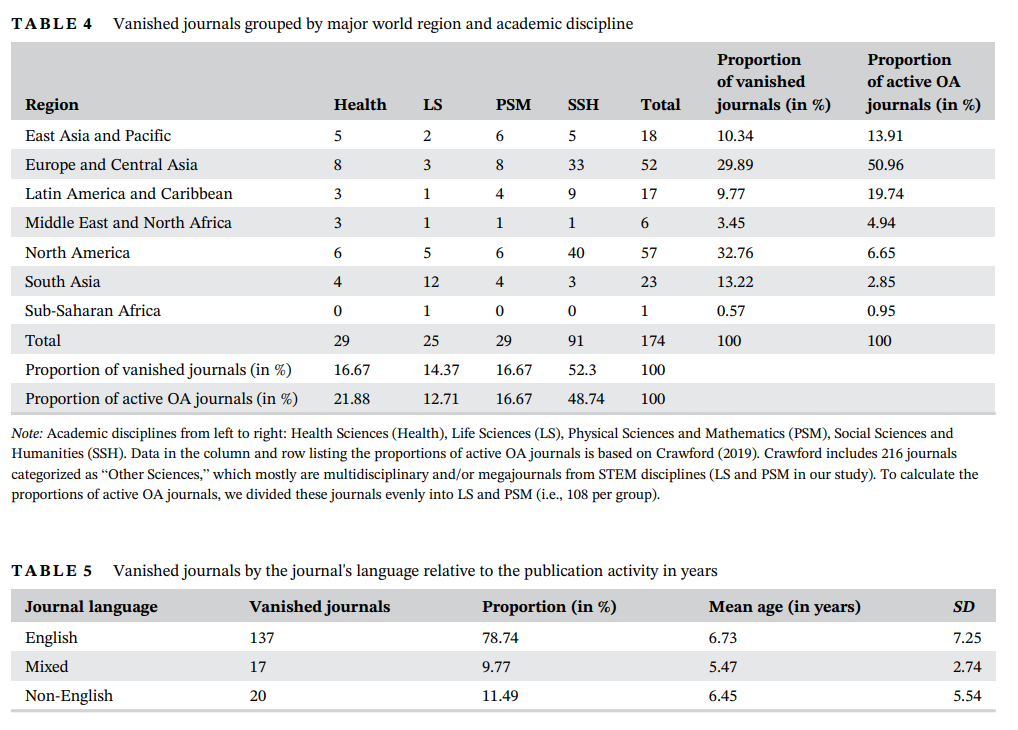
Źródło grafiki artykuł Open is not forever: A study of vanished open access journals
zanikający FLASH
Z końcem 2020 roku Microsoft ogłosił, że nie będzie wspierał technologii Flash w swoich przeglądarkach, inni producenci przeglądarek jak Google Chrome w lipcu 2019, Mozilla w styczniu 2021, Safari we wrześniu 2020. Zniknął ogromny zasób internetu w postaci stron, animowanych treści, gier. Sam obsługuję klienta, który miał ekologiczną grę dla dzieci we Flashu, która działała do momentu, aż FLASH przestał być dostępny i możliwy do uruchomienia bez specjalistycznej wiedzy. Co najważniejsze mało kto zdecyduje się na uruchamianie treści flash z powodu braku aktualizacji bezpieczeństwa. Kto nie zrobił konwersji gier, stron, animacji na nowe formaty, to został wykluczony. I tak gra ekologiczna już nie jest dostępna dla dzieci. Czytaj więcej o tym temacie w Żegnaj, Flashu na Google Search Central Blog w Google for Developers
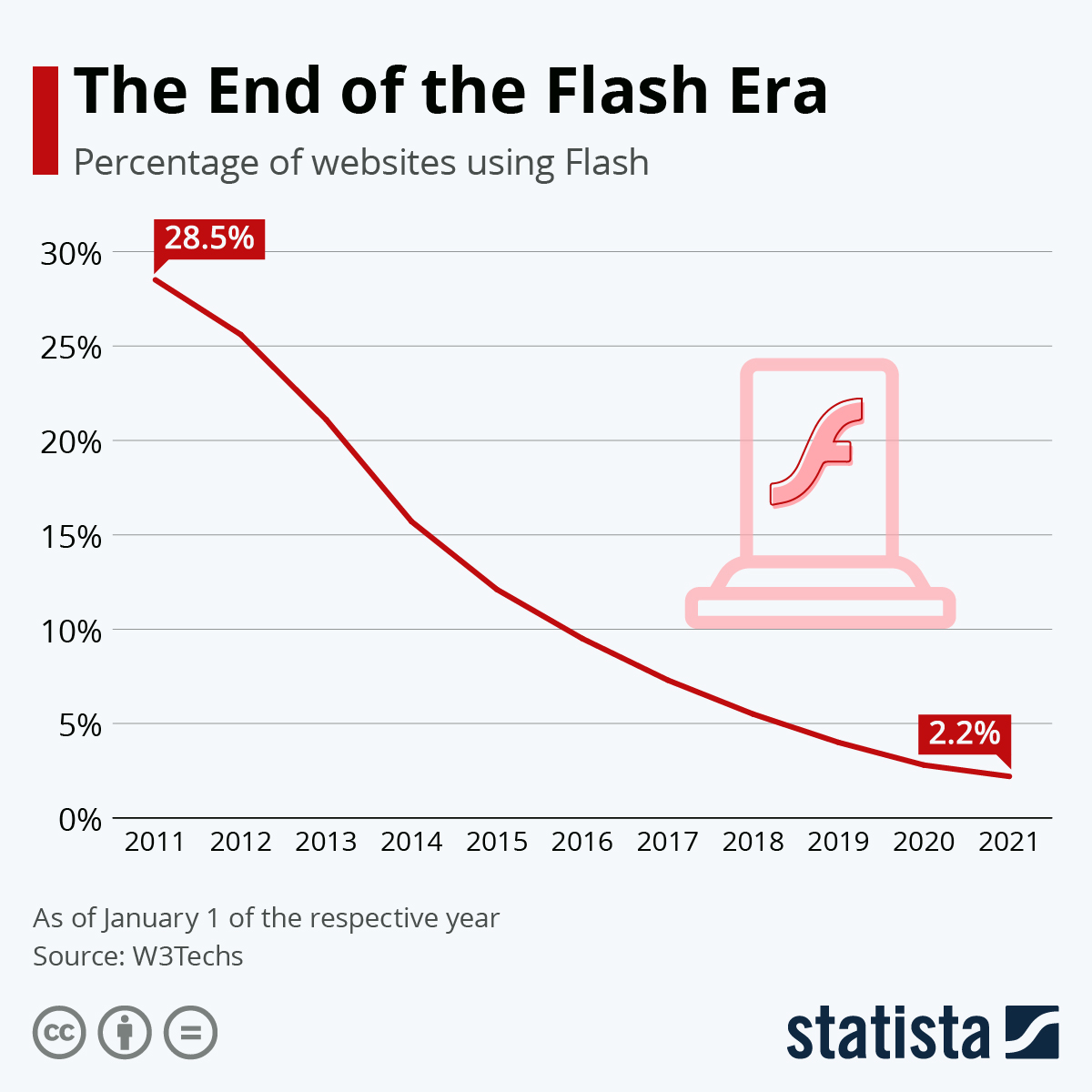
The End of an Era – Next Steps for Adobe Flash - Microsoft Edge Blog (windows.com)
Indeks Google jako Palimpsest cyfrowy
Palimpsest to starożytny rękopis spisany na używanym już wcześniej materiale piśmiennym, czyli po prostu ktoś zdrapał, albo usunął poprzedni tekst, aby następnie nanieść na to kolejną warstwę tekstu. Wykorzystam dzisiaj analogię palimpsestów ponieważ pomoże mi to w wyjaśnieniu wam złożonego problemu zanikających informacji w Internecie. Indeks wyszukiwarki Google przekształcił się w centralny zasób zbiorowej pamięci ludzkości, będąc autorytatywnym magazynem wiedzy i informacji o znaczącej reputacji. Tym samym zajmiemy się znaczeniem pamięci i dostępu do informacji dla społeczeństwa i człowieka w szczególności.
Zanim wyjaśnimy problem palimpsestu musimy prześledzić trochę historii rozwoju algorytmu wyszukiwarki oraz omówić pewne techniczne aspekty. Bez tego zrozumienie problemu będzie praktycznie niemożliwe.
3 etapy działania wyszukiwarki Google
Aby zrozumieć jak jest budowany i jak działa największy zasób pamięci zbiorowej obecnie, który nazywamy wyszukiwarką Google odwołam się do opisu na stronie twórców:
Wyszukiwarka Google działa w 3 etapach i nie wszystkie strony przechodzą przez każdy z nich:
Skanowanie: Google pobiera tekst, obrazy i filmy ze stron znalezionych w internecie, korzystając z automatycznych programów nazywanych robotami. Poznaj szczegóły dotyczące robotów indeksujących - Omówienie robotów (klientów użytkownika) Google | Centrum wyszukiwarki Google | Documentation | Google for Developers
Indeksowanie: Google analizuje tekst, obrazy i pliki wideo na stronie, a następnie przechowuje informacje w indeksie Google, czyli w dużej bazie danych.
Wyświetlanie wyników wyszukiwania: gdy użytkownik wyszukuje informacje w Google, wyszukiwarka zwraca informacje pasujące do jego zapytania.
Jak działa wyszukiwarka Google | Centrum wyszukiwarki Google | Documentation | Google for Developers
Jak generowany jest wynik wyszukiwania w Google?
Przedstawię poniżej ogólne zasady i elementy jakie budują generowanie wyniku, co jest brane pod uwagę przy generowaniu wyniku wyszukiwania przez algorytm Google. Wynik wyszukiwania to SERP (search engine result page) zaś sam algorytm to zestaw procedur, które dostarczają informację do SERP i decydują o wartości oraz sposobie wyświetlania. Warto dodać, że sam algorytm jest najbardziej chronioną tajemnicą Google i opisując poniższe składowe bazujemy na ogólnie dostępnych informacjach.
Crawlery skanujące strony i treści opublikowane w Internecie dzielą się na odkrywcze (discovery) oraz odświeżająco/monitorujące (refresh) - są to programy zwane także jako roboty indeksujące. Analizują one treść, strukturę strony i dostarczają analizowane informacje do centrów danych. Aby zapewnić jak najlepsze analizy roboty skanują strony z różnych lokalizacji, a zawartość indeksu jest później ustalana i synchronizowana pomiędzy DataCenter (różnica w wynikach zależna od DataCenter to efekt Google Dancing). To roboty i ich częste odwiedziny stoją za monitorowaniem czy są włamania na stronę, czy jest tam spam, czy zmieniła się treść na niezgodną z regulaminami. Jeśli robot nie natrafi na treść algorytm dostaje sygnał, że dzieje się coś złego.
JAKOŚĆ TREŚCI - dla Google osoba wyszukująca jest Klientem, dlatego analizuje treść i jakość skanowanej informacji na stronie, żeby była jak najbardziej dopasowana do tego czego wyszukuje w zapytaniu Klient. Analizując treść strony sprawdza się reputację cytowania, linkowania, ma miejsce analiza antyspamowa czy nie mamy do czynienia z duplikatem treści albo synonimizowanym tekstem wygenerowanym automatycznie - ma to zapobiegać manipulacjom trafności i rzetelności dostępu do informacji.
TRAFNOŚĆ TREŚCI - analizuje się tutaj słowa kluczowe, czyli po prostu bardziej szczegółowy proces semantycznego dopasowania do trafności PYTANIE <> POTENCJALNA ODPOWIEDŹ. Analizowana jest nie tylko warstwa tekstowa ale anonimowe dane z użytkowania stron, które przekształca się w sygnały.
ZNACZENIE ZAPYTANIA - (ranking result) ustalenie jakich informacji się szuka - modele językowe ustalają semantykę i decydują o segmencie najbardziej odpowiednich treści oraz języku w jakim ma być realizowane wyszukiwanie. Ranking popularności co oczywiste promuje w czasie nowsze i bardziej popularne wyniki jednocześnie obniżając reputację starszych.
UŻYTECZNOŚĆ TREŚCI weryfikuje się jakość strony, wykonanie techniczne, dopasowanie sposobu prezentacji, typografii i dopasowania do ekranu urządzenia.
KONTEKST I USTAWIENIA tutaj brane są pod uwagę parametry charakterystyczne dla konkretnego użytkownika, czyli cookies, lokalizacja i wynikające z historii personalizacje wyników, rodzaj i ustawienie urządzenia.
źródło: Ranking wyników wyszukiwania - Google Search
Jednak powyższe 5 elementów to ogólny zarys ponieważ graf wiedzy (knowledge graph) jest kluczowy w generowaniu i indeksowaniu wyników wyszukiwania w kontekście semantycznej sieci (powiązań znaczeń) i integracji. Będzie to szczególnie ważne, ponieważ w rozdziale Algorytm jako ciągły proces pokażę, jak graf wiedzy jest wykorzystywany w tym kontekście. Znaczenia są realizowane na poziomie całości, a nie poprzez analizę poszczególnych elementów. Wróćmy teraz do semantyki.
 Ilustracja: Semantyczna sieć. A semantic network approach to measuring sentiment | Quality & Quantity (springer.com)
Ilustracja: Semantyczna sieć. A semantic network approach to measuring sentiment | Quality & Quantity (springer.com)
Semantyczna sieć oraz Graf Wiedzy (knowledge graph) - interpretuje zapytanie użytkownika w kontekście jego znaczenia, a nie tylko słów kluczowych. Pozwala to na tzw. rich results, czyli bardziej trafne wyniki. Co ciekawe filozofia jaka za tym stoi została wprowadzona w okolicy 2012 roku, był to przełom w historii wyszukiwarek (odnotuj to drogi Czytelniku!), jednak dopiero AI pozwoliło na prawdziwe dopracowanie algorytmu. Taka sieć semantyczna umożliwia tworzenie połączeń pomiędzy znakami, obiektami i znaczeniami (a od ponad 4 lat niezależnie od języka). Przykładowo szukając zapytania “Leonardo da Vinci” graf wiedzy powiąże zapytanie semantycznie z informacjami o dziełach Leonardo, jego życiu ale także wpływie na sztukę (np. z pojęciami “renesans”, “malarstwo” i “artysta”). Jak widać pozwala to na znaczne rozszerzenie wiedzy poprzez jedno proste zapytanie. Jeśli chcesz wiedzieć więcej o semantycznej sieci: A semantic network approach to measuring sentiment
Znaczniki uporządkowanych danych - Co ważne, musisz stosować odpowiednią technologię znaczników uporządkowanych danych co zapewnia standard do interpretowania i prezentowania danych w grafie wiedzy. Tworzy to możliwe segmenty / szufladki dla treści pozwalające na oznaczanie zawartości stron i informacji tam zawartych tak, aby były one zrozumiałe do robotów indeksujących czyli wyszukiwarek. Pozwala też algorytmowi na realizację powiązań semantycznych.
wysoki próg wejścia do indeksu?
Tak więc jeśli chcesz być częścią tego wspaniałego uniwersum i dostarczać treści użytkownikom wyszukiwarek, czyli być częścią grafu i zwiększyć widoczność udostępnianych przez ciebie informacji bądź wiedzy, to musisz stosować się do standardu określonego przez schema.org. Jeśli tego nie robisz, to twoje informacje nie będą częścią semantycznej sieci jaką zaprojektował m.in. Google. Efekty? Często strony o charakterze komercyjnym albo napompowane reklamami są promowane, ponieważ ich konstrukcja techniczna jest doskonale dopracowana i dominuje nad stronami gorszymi technicznie i bez danych strukturalnych.
Błędne zastosowanie schema wprowadza algorytmy w błąd i może dać sygnał wykluczenia z indeksu. Co ciekawe mamy też efekt dominujących witryn takich jak wikipedia, gdzie masowe i dobrze jakościowo zastosowane schema powodują dominację w wynikach wyszukiwania często nad lepszymi jakościowo artykułami wypierając tym samym mniejsze strony, które oferują unikalne podejście albo zawierają ciekawe analizy. Mam tutaj na myśli nie tylko blogi, ale także strony uczelni. (Znaczniki uporządkowanych danych obsługiwane przez wyszukiwarkę Google | Centrum wyszukiwarki Google | Documentation | Google for Developers)
Jeśli zainteresował Ciebie problem Schema oraz indeksowania i algorytmów, to zdecydowanie polecam zapoznać się z artykułem: Autonomous schema markups based on intelligent computing for search engine optimization - PMC Nie jest to może najświeższa wiedza, ale nadal aktualna i ciekawa.
Tutaj sygnał dla moich Czytelników, ponieważ wiele teorii spiskowych jakie powstają właśnie jest na tym poziomie, czyli kto tworzy te standardy i jakie firmy wchodzą w składy konsorcjów… tak, big tech. Czyli warto zwrócić uwagę na krytykę sposobu tworzenia np. standardów dla danych strukturalnych, czyli fakt, iż określanie standardów jest scentralizowane może nosić znamiona politycznej dominacji i manipulacji poprzez np. wykluczanie pewnych informacji oraz nie tworzenie pewnych segmentów treści przez co będą one zanikały.
DeNardis (2009, 2014) and Russell (2011, 2014) detail the governance of internet infrastructure by examining the roles that institutions such as W3C play where information is controlled, manipulated, and eventually commodified by platform companies. […]
Researchers have foregrounded these explicitly political issues related to networked semantics on the web. Waller’s (2016) and Poirier’s (2017, 2019) ethnographic studies examine how infrastructures on the semantic web (e.g., taxonomies, schemas, and ontologies) are built and reveal the power dynamics embedded in their creation and use.
 Ilustracja: Spadek wizyt (rdr był wzrost) na Wikipedia po wprowadzeniu Schema i rich results w SERP Google.
Ilustracja: Spadek wizyt (rdr był wzrost) na Wikipedia po wprowadzeniu Schema i rich results w SERP Google.
Co ciekawe wprowadzenie grafu wiedzy przez Google i ulepszenie wyników wyszukiwania w SERP spowodowało w 2013 roku spadek wizyt na Wikipedii w porównaniu rok do roku, ponieważ informacja była wyświetlana wprost w SERP i użytkownik nie musiał wchodzić głębiej. Is Google accidentally killing Wikipedia? (dailydot.com)
algorytm jako ciągły proces (BERT/MUM)
Jako ciekawostkę modyfikacji algorytmu można podać pandemię COVID19, gdy w 2020 roku zmieniło się behawioralne zachowanie użytkowników poprzez lockdowny, zamknięto sporo biznesów, ale nastąpił też raptowny wzrost użycia urządzeń mobilnych i sprzedaży internetowej. To wszystko wymusiło zmiany i poprawki algorytmu, które musiały odzwierciedlać sytuację pandemiczną.
W 2021 roku miało miejsce około 9,5 zmian w algorytmie Google dziennie na produkcji, a łącznie około 3467 w całym roku, natomiast w 2022 było to 4725 zmian na produkcji (12 dziennie) [źródło Google Dev]. Widzimy w ostatnich latach raptowny rozwój wyszukiwarki. Dla porównania w całym 2009 roku było to między 350-400 poprawek. Oznacza to, że analizując wyniki wyszukiwania nie możemy wyróżnić wzorca, bo są mniej spójne i możliwe do przewidywania w czasie, ponieważ następuje zbyt wielki rozwój algorytmu i drobnych zmian/poprawek w czasie. Co nie oznacza, że dostarczane informacje nie są trafne i użyteczne. Dla branży SEO spamerów to koszmar, bo oznacza permanentny proces adaptacyjny do zmian i szukanie nisz w pompowaniu treści. Ale problem nie dotyczy tylko branży SEO spamerów, ale także firm i treści masowo wykluczanych oraz których reputacja jest obniżana, zaś zasady tworzenia wyników SERP są coraz mniej jasne.
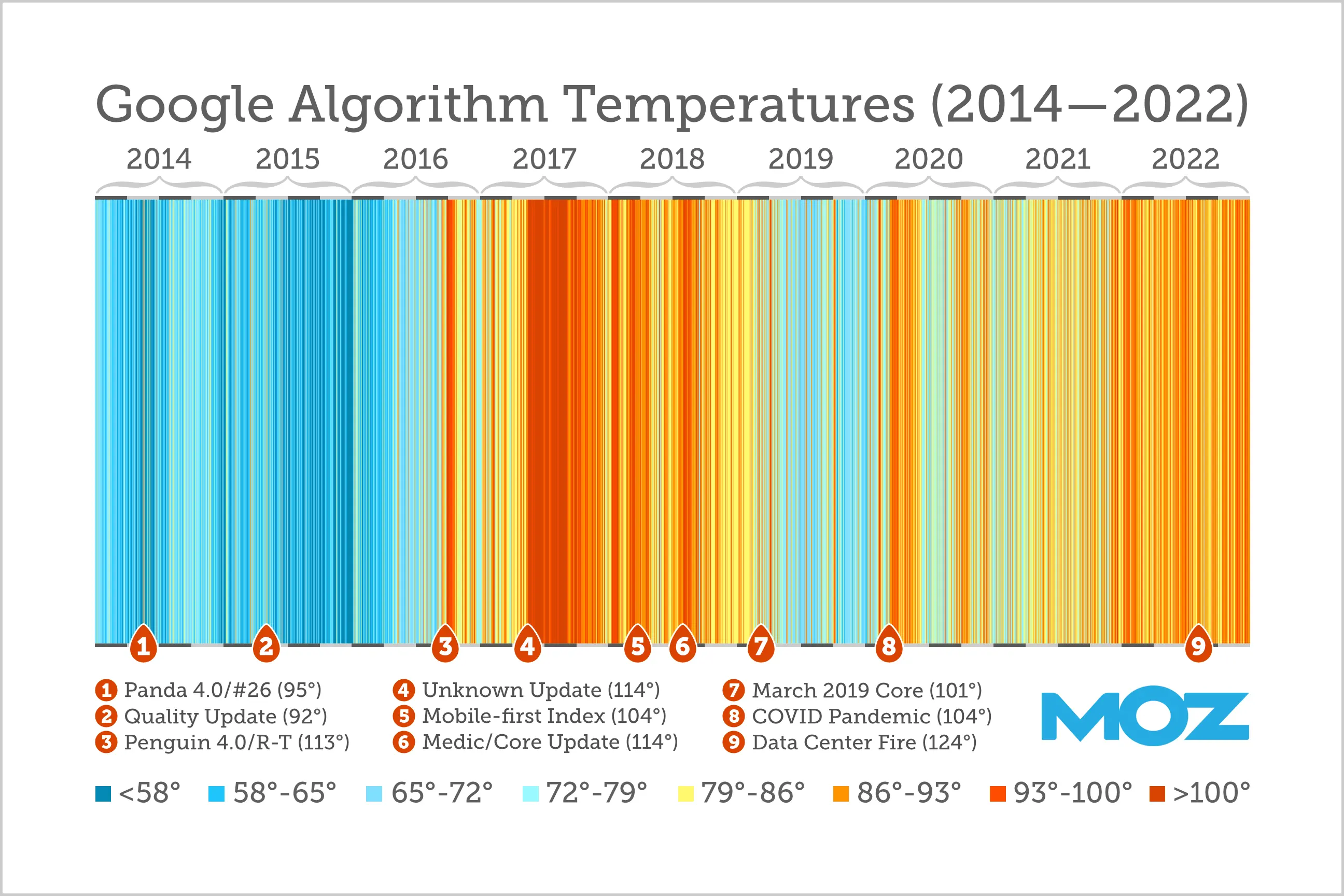 Ilustracja: z artykułu 9 Years of the Google Algorithm - Moz
Ilustracja: z artykułu 9 Years of the Google Algorithm - Moz
Użycie sztucznej inteligencji pozwoliło na znaczną poprawę wnikania w coś co możemy określić jako intencje i motywacje stojące za konkretnym wyszukiwaniem. Oznacza to, że za sprawą AI, a dokładnie zaawansowanych modeli BERT (Bidirectional Encoder Representations from Transformers) i MUM (Multitask Unified Model) mamy możliwość na lepszą analizę semantyczną informacji w kontekście języka naturalnego. Czyli BERT pozwala na rozumienie całego zdania bez analizy poszczególnych słów. Natomiast MUM to krok dalej, czyli przetwarzanie nie tylko języka na poziomie BERT, ale również analizy semantycznej w wielu językach oraz innych formatach nośników znaku np. obrazu. Co najważniejsze analizuje je wielopoziomowo jednocześnie.
Reasumując BERT nauczył Google lepszego zrozumienia języka, podczas gdy MUM wykorzystuje tę lekcję, aby zrozumieć nie tylko słowa, ale także kontekst, intencje i złożone zapytania na zupełnie nowym poziomie. Ciężko mi znaleźć metaforę albo analogię, która miałaby pokazać różnicę i raptowny rozwój tej technologii. Nie wnikając w szczegóły techniczne Google ma możliwość doskonałego przewidywania na podstawie danych behawioralnych, profilowania i segmentowania tego, czego szuka użytkownik i prawdopodobnie dlaczego szuka, chociaż Google zapewnia, że nie profiluje rasowo, politycznie i seksualnie…
wykluczanie z indeksu vs ciągła adaptacja do zmian
Mam nadzieję, że pokazałem wam, iż algorytm Google to proces poddawany ciągłym ulepszeniom. Dlatego, aby zapewnić widoczność Twojej strony w Internecie i uniknąć jej marginalizacji czy zanikania, należy mieć na uwadze, że strategie, które są skuteczne dziś, mogą nie przynosić rezultatów jutro. Wymaga to zatem kompetencji i ciągłego śledzenia zmian tak, aby dostosowywać i korygować strukturę, formę prezentacji a także reagowanie na potencjalne problemy. Na podstawie mojego doświadczenia, strony zoptymalizowane i zgodne z aktualnymi trendami, zawierające wartościowe treści, mogą przez pewien czas utrzymać swoją widoczność w wynikach wyszukiwania. Co to oznacza? Musisz być przygotowany na koszty albo samemu poświęcać czas na monitorowanie zmian algorytmów i komunikatów Search Central.
Za selekcją treści stoi system AI i system uczenia maszynowego o nazwie SpamBrain. W 2019 roku każdego dnia Google wykrywał 25 miliardów spamerskich stron, a 2022 roku systemy Google wykryły około 40 miliardów spamerskich stron dziennie. Realizowane jest to automatycznie, ale także przez zespół, który wdraża ręczne działania (kary) i oznacza strony obniżając ich reputację albo wykluczając z indeksu. Często takie oznaczenie wynika z np. włamania na stronę i modyfikacji takiej, że wyświetla w treści miliony linków do środków farmaceutycznych (Rok w wyszukiwarce – raport o spamie na stronach internetowych w roku 2018 | Google Search Central Blog | Google for Developers). W 2018 roku Google wysłało ponad 180 milionów wiadomości do właścicieli stron z komunikatem o problemach ze spamem. Brak reakcji na błędy krytyczne oznacza najczęściej wykluczenie z indeksu albo takie obniżenie reputacji, że nikt Twojej treści nie znajdzie. W Wyniku wyszukiwania stosuje się też oznaczenie, że strona jest niebezpieczna dla użytkownika i odradza się wejście na taką stronę. Dotyczy to także braku HTTPS albo wadliwego certyfikatu.
Ciekawa sytuacja miała miejsce w sierpniu 2019 gdy Google z powodu braku zasobów do przetwarzania nowych linków oraz ujednolicania stanu indeksu (tzw. google dancing) pomiędzy data center zaliczyło awarię, co przerwało możliwość indeksowania i zepsuło indeks. Problemy z indeksowaniem: jak rozwiązaliśmy je w przypadku wyszukiwarki Google i czego się nauczyliśmy? | Google Search Central Blog | Google for Developers Nie będę tego omawiał jednak warto zwrócić na ten aspekt uwagę, ponieważ wskazuje, że póki co infrastruktura serwerowa i algorytmy tworzone przez inżynierów są realizowane poprzez ludzkie planowanie i decyzje, często motywowane wynikami finansowymi, obarczone kalendarzem (weekend i mniejsze zasoby ludzkie) i tak jak wszystkie twory człowieka tutaj też możemy mić do czynienia z błędami. Dlatego w algorytmach jak również infrastrukturze realizuje się ciągłe poprawki i korekty i można powiedzieć, że jest to proces poddawany ciągłym modyfikacjom.
obniżanie reputacji i ukrywanie informacji
Jest oczywiście wada tego rozwiązania polegająca na tym, że jeśli szukamy informacji, to algorytm może nie przewidzieć poprawnie naszych motywacji i intencji nawet jeśli przyjmie paranoiczną postawę przełamującą schemat i bezpieczniki zaprojektowany przez inżynierów. napisałem o paranoicznej ponieważ budując Czytelnika Modelowego jeśli ten wykracza poza schemat algorytmu, to jest semantyka paranoiczna (niezgodna z założonymi znaczeniami). Technologia BERT/MUM pozwala także Google rzekomo zwalczać dezinformację oraz fake newsy, co raczej podważają badacze - patrz doskonały artykuł Jak użytkownicy wyszukiwarek wpadają w króliczą norę? (demagog.org.pl). Problem w tym, że organizacje factcheckingowe walczące z dezinformacją i teoriami spiskowymi mają pełną przejrzystość działania i prezentują metodologię oraz proces analizy informacji. Natomiast proces prezentacji informacji w SERP Google jest utajony. Pytanie ile Google będzie wykluczał, ukrywał, obniżał reputację informacji na podstawie politycznych decyzji albo geopolitycznych interesów? Oczywiście najbardziej znanym jest przypadek obecności Google w Chinach i cenzury wyników wyszukiwania w latach 2006-2009 wikipedia.
Jeśli nie mamy przejrzystości działania algorytmów dostarczających informacje, to łatwo taki proces generowania pamięci zbiorowej w postaci SERP może być krytykowany przez teoretyków spisku zarzucających nadużycia i cenzurę. Firma Google jako spółka notowana na giełdzie jest prywatnym podmiotem z udziałowcami wpływającymi na strategię rozwoju.
Podsumowanie
W świecie rozkładu prawdy i powszechnego braku zaufania wobec wszelkich instytucji publicznych uniwersytety mają do odegrania szczególną rolę, nie tylko jako wiarygodne źródło rzetelnych informacji i bezpieczna przestrzeń rzeczowej debaty, lecz także jako katedra, z której popłyną słowa prawdy - prosto w oczy niepoddandej żadnej kontroli władzy. (Loc 4452) - Ronald J. Deibert Wielka inwigilacja.
Dzisiejszy artykuł zawierał wiele skomplikowanych spraw związanych z indeksem Google i nie dla każdego może być przystępny. Niestety nie mogłem tego przeskoczyć i uznałem, że nie da się przedstawić zanikania bez prezentacji mechanizmów oraz rozwoju indeksowania jako technologii. Mam nadzieję, że wskazałem pewne wektory problemów oraz opis techniczny, który pozwoli ci zrozumieć powagę problemu. Żyjemy w cyfrowym świecie, gdzie odczytując palimpsest cyfrowy narzuca nam się interpretację jednocześnie ukrywając albo wyszczególniając pewne informacje. Prowadzi to do powstawania teorii spiskowych, wpadania w królicze nory o których pisał serwis Demagog.org.pl Chciałbym, aby mój artykuł stanowił wkład w rozwój nie tylko mechanizmów dostarczania i obiegu informacji, ale także refleksji nad tym jak raptowny rozwój AI w przewidywaniu intencji człowieka i dostarczaniu systemu znaczeń wpłynie na nasz świat.
Jednocześnie sygnalizuję, że wyciąłem całe rozdziały dotyczące cyfrowej śmierci, sieci społecznościowych, a także statystyk wraz z parametrem poziomu odrzuceń, które są bardzo interesującymi zagadnieniami, ale przez wzgląd na ilość nadają się na osobny artykuł. Całe rozdziały poświęcone prezentacjom projektów próbujących zachować zasób cyfrowej pamięci zbiorowej i zachowania cyfrowego dziedzictwa z niuansami dotyczącymi kwestii technicznych, problemów, licencjonowania również postanowiłem wyciągnąć potencjalnie na trzeci artykuł.
Wybrana Bibliografia
Google Search Status Dashboard
Moz - Google Algorithm Update History
Wykrywanie spamu – jak działa wyszukiwarka Google
9 Years of the Google Algorithm - Moz
Open is not forever: A study of vanished open access journals (arxiv.org)
More than 100 scientific journals have disappeared from the Internet
Palimpsest (piśmiennictwo) – Wikipedia, wolna encyklopedia
Let’s talk about digital death | Request PDF (researchgate.net)
Open is not forever: A study of vanished open access journals (arxiv.org)
Google’s fact-checking bots build vast knowledge bank | New Scientist Semantic Network - Wikipedia

Wzmacniaj Sygnał
Najlepszym wsparciem jest udostępnianie artykułów i oznaczanie dadalo.pl w mediach społecznościowych. Możesz też wesprzeć finansowo - pokrywa to dostęp do mediów i archiwów prasowych potrzebnych do badań.


