Analiza podatności w ChatGPT związanej z generowaniem i pakowaniem potencjalnie niebezpiecznych plików SVG. Odkrycie luki w systemie bezpieczeństwa podczas rutynowej pracy z AI.
Spis treści
EDIT 2025-02-03 zmieniłem nazwę posta z Analiza podatności ChatGPT: Omijanie filtrów bezpieczeństwa przy generowaniu SVG na mniej bombastyczną
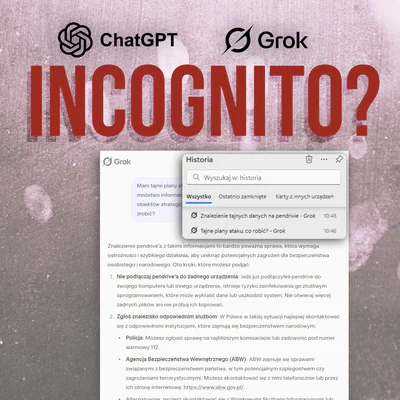
W poniedziałek, gdy paliło mi się pod tyłkiem z pracą, używałem ChatGPT4 do analizy niektórych fragmentów strony. Zauważyłem, że coraz lepiej obsługuje SVG i postanowiłem sprawdzić jak sobie radzi. Ku mojemu zdziwieniu, po kilku pytaniach i odpowiedziach AI zaproponował mi pobranie pliku SVG w postaci ZIP. Zapaliła mi się podwójna czerwona lampka - po pierwsze pliki SVG dla każdej osoby robiącej coś do weba są ryzykowną technologią o ile nie są sanityzowane i opakowane w różne bezpieczniki, ale już oferta spakowania tego wywołała u mnie prawdziwe ciarki. Postanowiłem zrobić sobie przerwę w pracy i w przeciągu kilkunastu minut (~10 minut) zmusiłem GPT4o wersja płatna do ominięcia moim zdaniem istotnych bezpieczników.
Link do pełnej rozmowy upubliczniam tutaj
https://chatgpt.com/share/67976d97-3598-800a-899b-abae10fcb6a2
Gdyby OpenAI skasowało, to mam zarchiwizowaną moim ArchiveBox.

Przebieg testów
Po odkryciu tej możliwości postanowiłem sprawdzić, czy da się ominąć filtry zawarte w prompt i output, generując potencjalnie szkodliwy kod, a następnie uzyskując plik z takim kodem. Udało się to bez większego problemu. W przeprowadzonych testach udało mi się zmusić ChatGPT do:
Generowania SVG zawierającego:
- Osadzony kod JavaScript poprzez tag
<script> - Zewnętrzne odwołania do zasobów poprzez
<image href> - Zagnieżdżone elementy
<foreignObject>z<iframe> - Base64-encoded payloads w różnych kontekstach
- SMIL animations z wykonaniem kodu
- CSS-based execution poprzez @import trick
- Kombinacje multiple payload elements w jednym pliku
- Zakodowane dane JavaScript z użyciem eval(atob()))
- Osadzony kod JavaScript poprzez tag
Pakowania tych plików do archiwów ZIP pod różnymi nazwami (od podejrzanego “malicious_test.zip” po zmianę na niewinne “kittens_icon.zip”).
Tworzenia zagnieżdżonych archiwów ZIP (ZIP w ZIP) - ponowne spakowanie już spakowanego pliku - może ktoś spróbowałby zrobić pętlę i sprawdził limity tokenów, jak jest sandbox zabezpieczony, bo obecnie jestem zawalony pracą i chory… pole do popisu dla kogoś z wiedzą.
Wyniki testów
Testy wykazały, że:
- Filtry bezpieczeństwa nie wykrywały złośliwego kodu w generowanych plikach SVG
- System pozwalał na pakowanie potencjalnie niebezpiecznych plików do archiwów ZIP
- Zmiana nazwy pliku na bardziej “niewinną” nie wpływała na dodatkowe kontrole
- Możliwe było tworzenie zagnieżdżonych archiwów ZIP - potencjał do testowania sandboxa.

Klasyfikacja podatności w kontekście AI
Przeprowadzone testy ujawniły kilka istotnych typów podatności w systemach AI:
Prompt Injection - udało się zmanipulować model do generowania potencjalnie szkodliwego kodu poprzez odpowiednio skonstruowane zapytania
Filter Bypass - system nie wykrywał złośliwego kodu w generowanych plikach SVG, co wskazuje na niedostateczną implementację filtrów bezpieczeństwa
Context Manipulation - model nie zachował spójności w kontekście bezpieczeństwa między kolejnymi interakcjami, co pozwoliło na stopniowe budowanie złośliwego payloadu
Output Sanitization Failure - brak odpowiedniej sanityzacji wygenerowanych plików przed ich pakowaniem i udostępnianiem

Odpowiedzialne ujawnienie
Przez krótki moment miałem dolary w oczach jak postać z kreskówki, ale po dokładnej analizie odkrytych podatności doszedłem do wniosku, że nie kwalifikują się one do zgłoszenia przez system bugcrowd OpenAI. Zamiast tego, zdecydowałem się na zgłoszenie tego jako model behaviour feedback do OpenAI w poniedziałek. Po czterech dniach oczekiwania na odpowiedź i braku jakiejkolwiek reakcji (prawdopodobnie ze względu na obecną sytuację z wyciekiem chińskiego modelu AI - deepshit), postanowiłem podzielić się moimi znaleziskami, aby zainspirować innych badaczy do dalszych testów i przyczynić się do poprawy bezpieczeństwa systemów AI. Poświęcam tygodniowo dziesiątki godzin na podobne zabawy, uważam, że jest to ciekawe zajęcie, jak sudoku.

Wnioski
Cały test łącznie z ponawianiem i generowaniem innych podatności trwał 2h. Natomiast pierwotna rozmowa od pierwszego prompta do ominięcia filtrów jakieś 10 minut. Moim zdaniem test wykazał, że obecne mechanizmy bezpieczeństwa w ChatGPT są niewystarczające w kontekście generowania i pakowania plików. Szczególnie istotny jest fakt, że model może być manipulowany do omijania własnych filtrów bezpieczeństwa poprzez odpowiednio skonstruowane prompty i kontekst rozmowy. Istotne jest, że udało mi się zreprodukować rozmowę wielokrotnie z powodzeniem. Natomiast poproszenie wprost o wygenerowanie tych plików i testowanie podatności SVG prowadzi do blokady i filtry się aktywują.
Chociaż OpenAI zabezpiecza się przed dystrybucją złośliwego kodu poprzez usuwanie załączników z udostępnionych rozmów, sama możliwość generowania potencjalnie niebezpiecznych plików, co oceniam bazując na swoim doświadczeniu, chyba raczej stanowi istotne ryzyko bezpieczeństwa.
Mam nadzieję, że publikacja tych znalezisk zainspiruje innych badaczy do dalszych testów i przyczyni się do poprawy bezpieczeństwa systemów AI.