AI slop i paradoks eksperta. Jak generatywne wyszukiwarki tworzą nowe błędy poznawcze – od konfabulacji Google AI po meta-autorytet Groka. O technologii, która wymaga nadmiaru wiedzy, by weryfikować narzędzia mające z niej zwalniać. Nowy świat szlachetnego kłamstwa.
Spis treści
W artykule aktywizm w cieniu błędów poznawczych i efektu potwierdzenia opisałem przypadek Adama Pustelnika i mechanizm błędu poznawczego wynikającego z Rich Results w Google. Tamten błąd był nazwijmy to “analogowy”, czyli wynikał z tego, jak ludzie skanują wyniki wyszukiwania na ekranie, nie wchodząc głębiej. Dzisiaj mamy problem znacznie poważniejszy: AI jako aktywny generator konfabulacji, nie tylko pasywny agregator linków. A ponieważ realizuje się teraz rewolucja w SERP oraz internecie warto przyjrzeć się temu problemowi głębiej.
Przypadek “EFF Everbridge”, czyli gdy AI tworzy nieistniejące pojęcia
Piszę aktualnie artykuł o systemach powiadamiania kryzysowego w USA. Everbridge to firma dostarczająca platformy do zarządzania zdarzeniami krytycznymi. Są to masowe alerty SMS, powiadomienia o klęskach żywiołowych. EFF to oczywiście Electronic Frontier Foundation, organizacja zajmująca się wolnościami cyfrowymi i prywatnością.
Postanowiłem sprawdzić, co Google w SERP (search engine result page - strona wyników wyszukiwania) pokaże na proste zapytanie “EFF everbridge”. Szukałem materiałów o potencjalnych kontrowersjach związanych z prywatnością przy masowym zbieraniu danych przez systemy alertów. Dwie frazy, czyli zlepek dokładnie tak, jak większość ludzi wyszukuje.
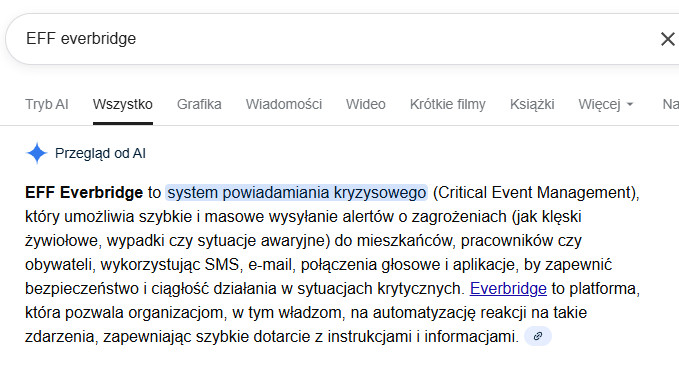
Otrzymałem to, co obecnie większość ludzi, czyli “Przegląd od AI” na górze wyników, który mówi mi, że “EFF Everbridge to system powiadamiania kryzysowego (Critical Event Management)”. Google AI połączyło dwie frazy i wygenerowało nieistniejące pojęcie, które brzmi jak ustalony termin techniczny. Dla kogoś bez kontekstu ta odpowiedź wygląda całkowicie wiarygodnie. Oczywiście proste sprawdzenie pierwszych liter po angielsku tego pojęcia pokazuje, że CEM to nie EFF. Ja oczywiście znam zakresy i definicje obu pojęć, więc dla mnie AI-slop (generatywny śmietnik) było czytelne.
Dopiero wejście w tryb AI (druga zakładka) daje poprawną odpowiedź:
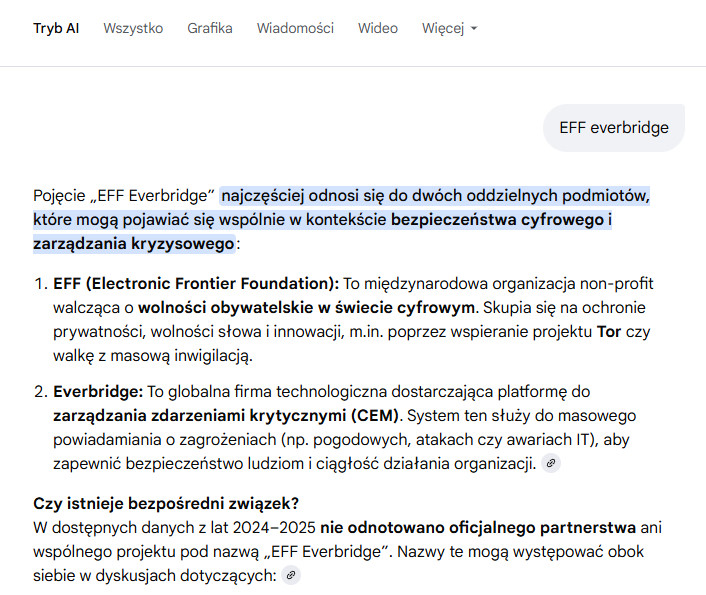
Tu Google wyraźnie rozróżnia: EFF to organizacja non-profit walcząca o wolności cyfrowe, Everbridge to firma technologiczna. I dodaje kluczową informację: “nie odnotowano oficjalnego partnerstwa ani wspólnego projektu pod nazwą EFF Everbridge”. Osobiście twierdzę, że tak jak w przypadku optymalizacji zapytań na poziomie GEMINI PRO mamy częściowo cachowanie oraz routing zapytań na różne modele (flash) co powoduje na podstawowym poziomie drastyczne rozjechanie semantyki (opisałem to w tekście Gemini PRO jest zepsute). Czyli po prostu model ma za mało mocy obliczeniowej, aby wyłapać prosty błąd CEM nie równa się EFF. Dopiero wejście głębiej aktywuje dodatkowe mechanizmy, które wyłapują osobno konteksty.
Problem: wyszukiwanie hasłowe w świecie generatywnych odpowiedzi
Google przez ponad 20 lat trenowało użytkowników do wyszukiwania hasłowego. Ten dramat wyszukiwania w SERP i hackowania wyników, ale przecież większość ludzi lubi prostotę. Nie potrafi tak naprawdę używać operatorów ani kontrolować semantyki. Ludzie idą na skróty. Wpisuje się po prostu kilka fraz, dostaje listę linków. Odbiorca sam ocenia źródła.
Jak bardzo ludzie idą na skróty? Dane z Semrush State of Search 2022 (analiza 160 milionów słów kluczowych) pokazują skalę problemu:
| Długość zapytania | % ruchu wyszukiwań |
|---|---|
| 1–2 słowa | 51% |
| 3–5 słów | 43% |
| 6–9 słów | 6% |
| 10+ słów | <1% |
Ponad połowa zapytań to jedno lub dwa słowa. Moje “EFF everbridge” mieści się w dominującej kategorii — i właśnie dlatego jest reprezentatywne dla tego, jak większość ludzi korzysta z wyszukiwarek.
Co więcej, badanie Backlinko (1801 sesji użytkowników) pokazuje jak wygląda interakcja z wynikami:
| Zachowanie użytkownika | Wskaźnik |
|---|---|
| Mediana czasu do pierwszego kliknięcia | 9 sekund |
| Użytkownicy scrollujący do dołu strony | 9% |
| Użytkownicy wchodzący na stronę 2 | 0.44% |
9 sekund do kliknięcia. Dziewięć. To nie jest czas na analizę źródeł — to skanowanie i reakcja na pierwszy wynik, który wygląda sensownie. A teraz ten pierwszy wynik to “Przegląd od AI” zajmujący górę ekranu.
W artykule o cyfrowym palimpsescie dokładnie opisałem model predykcji AI budujący właśnie odbiorcę modelowego w Google (BERT/MUM) dzięki czemu właśnie te wyniki wyszukiwania kontekstualnie są tak dopasowane. Ten model działał, a błędy poznawcze wynikały z lenistwa użytkowników (skanowanie nagłówków zamiast czytania), ale przynajmniej odpowiedzialność za interpretację leżała po stronie człowieka. Korzystali na tym spamerzy oraz cały przemysł marketingu.
Teraz ten sam zlepek fraz generuje autorytatywnie brzmiącą narrację. Dla większości ludzi ten wyróżniony fragment strony w Google, który zyskał większą reputację niż uniwersytety to jest znacząca i fundamentalna różnica. Wcześniej Google mówiło “oto strony, które mogą zawierać odpowiedź”, teraz mówi “oto odpowiedź”. A ta odpowiedź może być czystą konfabulacją.
Fasada wiarygodności: co AI search dziedziczy po Google
Jednak nawyki ukształtowane przez 20 lat wyszukiwania hasłowego, co zawdzięczamy monopoliście Google, przenoszą się do generatywnych wyszukiwarek, ale już z poważniejszymi konsekwencjami. Badacze ze Stanford University przeprowadzili audyt czterech popularnych systemów (Bing Chat, NeevaAI, perplexity.ai, YouChat), analizując 1450 zapytań z różnorodnych źródeł.
| Metryka | Wynik | Interpretacja |
|---|---|---|
| Fluency | 4.48/5 | Odpowiedzi brzmią płynnie i profesjonalnie |
| Perceived utility | 4.50/5 | Użytkownicy oceniają je jako pomocne |
| Citation recall | 51.5% | Tylko połowa twierdzeń ma pokrycie w źródłach |
| Citation precision | 74.5% | 1/4 cytowań nie wspiera powiązanych twierdzeń |
Kluczowy wniosek jaki nas interesuje to korelacja między postrzeganą użytecznością a precyzją cytowań wynosi r = -0.96. Im bardziej odpowiedź “wydaje się pomocna”, tym częściej zawiera niepoparte twierdzenia. Systemy kopiujące ze źródeł (wysoka precyzja) są postrzegane jako mniej użyteczne. Dzieje się tak, bo użytkownicy preferują “twórczą” syntezę, która jednak częściej mija się z prawdą.
Jednak nie bądźmy tacy surowi względem algorytmów i AI, bo ten mechanizm dziedziczenia zawdzieczamy Google, który latami wytrenował nas na szybkie skanowanie i zaufanie do pierwszego wyniku. AI search produkuje płynny, przekonujący tekst którego użytkownik nie weryfikuje, bo “wygląda wiarygodnie” i się fajnie czyta.
Przytaczane tu badania Stanford z maja 2023 pokazują w mojej opinii rąbek skali problemu: około 50% odpowiedzi generatywnych wyszukiwarek nie ma żadnych cytowań źródłowych, a 25% podanych cytowań nie wspiera faktycznie przedstawionych twierdzeń. To się zmienia, ale powiedzmy sobie szczerze ile ludzi klika kontekst i kolejny wynik? Badacze odkryli odwróconą korelację: “najbardziej płynne i przekonujące odpowiedzi są najmniej prawdopodobne, że będą poparte źródłami, podczas gdy najbardziej niezdarne odpowiedzi są lepiej udokumentowane”. Czy wynika to z semantyki i tego, że gładkie słówka i korporacyjny bełkot to jest właśnie AI-style, a niezdarne i przez to nieszablonowe wypowiedzi są lepiej rozpracowywane jako encje przez AI?
Coś czego nie rozumie wiele osób, to zastosowanie techniki odwrócenia intuicji albo inaczej testowania paranoicznych interpretacji i ich falsyfikowania. W normalnym świecie im bardziej przekonująco coś brzmi, tym bardziej mu ufamy. W świecie AI slop powinniśmy stosować dokładnie odwrotną heurystykę. Jednak z naciskiem na falsyfikowanie, czyli weryfikację.
Paradoks eksperta: żeby wiedzieć, że AI kłamie, musisz już coś wiedzieć
No i właśnie ta falsyfikacja o której tyle piszę w kontekście teorii spiskowych, to tu właśnie dochodzimy do sedna problemu epistemicznego. Ja wiedziałem, że EFF to Electronic Frontier Foundation. Obserwuję ich publikacje i działalność od lat. Wiedziałem, że Everbridge to osobna firma. Dlatego natychmiast zobaczyłem konfabulację. Ale gdybym nie miał tej wiedzy na wejściu? Oczywiście uważny obserwator zobaczy błąd CEM nie równa się EFF o którym wspomniałem wyżej.
Dla laika “EFF Everbridge jako system powiadamiania kryzysowego” brzmi jak opis ustalonego, istniejącego pojęcia. Nie jak fantazja systemu statystycznego. Konfabulacja ubrana jest w język faktów. Myślę, że osoby odbierające bezkrytycznie urobek AI, tak jak dziennikarka Karolina Opolska, która rzekomo napisała książkę kopiując z AI (bazuję na doniesieniach prasowych i publikacjach specjalistów) nie tyle idą na łatwiznę, co prawdopodobnie nie mają po prostu kompetencji.
To jest paradoks eksperta: żeby natychmiast zidentyfikować AI slop, musisz już posiadać wiedzę, której szukasz. Bez niej potrzebujesz kompetencji krytycznych i czasu na weryfikację — a w erze 9-sekundowego skanowania na jedno i drugie mało kogo stać. W warstwie epistemicznej, poznawczej, to katastrofa.
Przesunięcie autorytetu: od źródeł do systemu
Jeśli pójdziemy dalej, to dojdziemy do czegoś, co obserwuję z rosnącym niepokojem. Autorytet przesuwa się z ludzi i źródeł, które mogą coś uzasadnić, na system reprodukujący statystyczne wzorce bez zdolności weryfikacji. Dlatego teraz, a właściwie od 2 lat mówię, że czas bajkopisarzy i ludzi z wąskimi specjalizacjami się skończył. Przyszedł czas ludzi z nadmiarem wiedzy i kompetencjami.
Musk rozwiązał problem szarego człowieka, zrobił genialny ruch. Muszę mu to przyznać, bo oczywiście “genialny” z jego perspektywy, bo z punktu widzenia świata i etyki ruch jest wątpliwy, ale przy skali zmian jakie obserwujemy Musk jest symptompem. Co on zrobił? Z jednej strony systematycznie rozwala tradycyjne autorytety tworząc poczucie, że walczy o wolność słowa i własny research. Uderza brutalnie w media, ekspertów, instytucje, dziennikarzy, naukowców. Z drugiej stworzył Groka, który stanowi element algorytmicznego meta-autorytetu, rzekomo “autonomiczny” i “nieocenzurowany”. Grok to jest taki dobry kumpel profesor z którym pogadasz o memach, ale także wyjaśni ci czy coś jest prawdą czy nie. Grokopedia czyli zamiennik wikipedii, której Musk nienawidzi to kolejna warstwa tego procesu, a którą Musk wprowadził jako alternatywną bazę wiedzy, która jest lepsza od woke-wikipedii.
Pluralizm źródeł przechodzi przez jeden filtr. To jest koncentracja wiedzy w rękach “filozofów królów”, o których pisałem wcześniej w nawiązaniu do Platona. Ci nowi filozofowie królowie nie tyle posiadają wiedzę, ile kontrolują semantykę i znaczenia. Opowiadają nowe mity. Decydują, co jest “prawdą”, nie przez argumentację, ale przez architekturę systemu. Warto dodać, że Platon wprowadził także koncepcję szlachetnego kłamstwa, czyli właśnie ci kontrolujący semantykę-mity mają prawo do naginania faktów, aby zarządzać motłochem.
Autorytet Google jest większy niż uniwersytetu
I tutaj jeśli zastanawiamy się nad epistemologią, czyli możliwościami poznawczymi i błędami poznawczymi warto nawiązać do badania “Epistemic Injustice in Generative AI” gdzie pojawia się pojęcie “wzmocnionej fałszywej wypowiedzi” (“amplified testimonial injustice”). Czyli obecnie jesteśmy na takim etapie rozwoju internetu, gdzie AI wzmacnia i powiela fałszywe narracje na skalę masową. Zgodnie z autorami tekstu system rzadko tworzy nowe kłamstwa — częściej wzmacnia istniejące błędy i uprzedzenia z danych treningowych. I robi to z autorytetem algorytmu, który dla wielu użytkowników jest większy niż autorytet ludzkiego eksperta. Jest wielu ekspertów którzy napisali bardzo dużo o tym jakie są potencjalnie zagrożenia za tym idące i tym zajmuję się w innych miejscach m.in. w tekście o manipulacji systemami rekomendacyjnymi. Warto jednak zwrócić uwagę na fakt, że autorzy wspomnianego tekstu nazywają to co opisujemy “hermeneutical access injustice” — nierówny dostęp do informacji i wiedzy zapośredniczony przez AI. Gdy jeden system staje się bramą do wiedzy, kontrola nad tym systemem staje się kontrolą nad tym, co ludzie mogą wiedzieć.
Doskonale powiedziane i w wielu głowach zapewne pojawia się teraz nazwisko Foucaulta, który powiedział, że władza to wiedza. Cóż, pozór wiedzy, a szczególnie kontrolowanie narracji, semantyki, to otwarte pole do kontroli. To jest taki meta poziom, ale na samym, najbardziej elementarnym poziomie ekranu, klawiatury mamy wykluczenie spowodowane kompetencjami pytającego (będącego zarazem odbiorcą komunikatu) moim zdaniem mamy tutaj do czynienia z asymetrią wiedzy czy asymetrii informacyjnej o której pisałem wielokrotnie wskazując jak dostęp do wiedzy i informacji może wykluczać ludzi z procesów np. na poziomie lokalnym.
Co zrobić z asymetrią informacyjną w dobie AI slop?
Edukacja i podnoszenie kompetencji to jest taka dobra rada jak mówienie osobie ciężko chorującej dbaj o zdrowie i uprawiaj sport. Nie zamierzam kończyć tego tekstu nihilizmem. W poprzednim artykule dałem konkretne zalecenia dla aktywistów. Tutaj sytuacja jest trudniejsza, bo problem jest systemowy, ale kilka rzeczy można zrobić.
Po pierwsze, zdaj sobie sprawę z paradoksu eksperta. Gdy szukasz informacji o czymś, czego nie znasz, AI jeśli nie masz kompetencji korzystania i researchu na poziomie OSINT jest najgorszym możliwym źródłem. Generatywne odpowiedzi są najbardziej niebezpieczne właśnie tam, gdzie najbardziej ich potrzebujesz. Moim zdaniem już od 10 lat powinny być w szkołach lekcje z tego co to SERP i jakie są zagrożenia SERP. Czy informacja zawarta w SERP jest wiarygodna. Takie szkolenia podobno są realizowane w Estonii.
Po drugie, wróć do źródeł. Research źródeł często do rozszerzenia kontekstu i nauki robię z pomocą AI (Gemini Deep Research, Claude Research, Perplexity), ale każdy wynik weryfikuję step-by-step. Następnie czytam źródła, słucham podcastów, wchodzę w temat głębiej. AI jest asystentem przy zbieraniu materiałów, nie wyroczną. Jeśli nie chcesz popełniać błędów jak Karolina Opolska, to zawsze, ale to zawsze, korzystając z materiałów dostarczanych przez AI musisz wchodzić w oryginalne źródła i sprawdzać cytowania (w książce Opolskiej o teoriach spiskowych cytowania były zmyślone). Jeśli nie zastosujesz takiej metodologii skończysz w trybie zombie promptingu z iluzją kompetencji.
Po trzecie, testuj i weryfikuj. Po prostu. AI najczęściej konfabuluje w konkretach: cytaty, statystyki, daty, nazwiska mniej znanych osób, numery publikacji. Musisz to jednak sprawdzić. Jest jednak klucz pewności - gdy odpowiedź zawiera takie elementy podane bez źródła - traktuj to jako sygnał do sprawdzenia. Im bardziej pewna sprawa, że np. ktoś kogoś rzekomo wykorzystał seksualnie, tym większy nacisk na weryfikację. Skuteczna metoda: poproś o źródło lub drąż szczegóły indywidualnie. Konfabulacje rozpadają się przy follow-upie, gdy fakty pozostają spójne. Mój wulgarny w prostocie test z “EFF everbridge” był celowy, po prostu chciałem zobaczyć, jak zachowa się tryb AI vs standardowy SERP. Codziennie mamy pewnie lepsze przypadku. Rób takie testy na tematach, które znasz. To buduje intuicję, gdzie systemowi można ufać, a gdzie nie.
Po czwarte, pamiętaj o efekcie potwierdzenia z pierwszej części. AI slop jest szczególnie niebezpieczny, gdy potwierdza to, w co już wierzysz. System jest trenowany na tym, żeby dawać odpowiedzi, które brzmią przekonująco, będą się podobały, a nie na tym, żeby mówić prawdę. Celem współczesnych algorytmów nie jest PRAWDA, czyli szybkie dotarcie do odpowiedzi, ale UWAGA i twój czas poświęcony w danym serwisie. Facebook jest chyba tego najlepszym przykładem.
Czy mamy jeszcze czas na uważność?
W poprzednim artykule pisałem o aktywistach, którzy tworzyli teorie spiskowe na podstawie wyniku wyszukiwania Google. Tamten błąd wynikał z ludzkiej skłonności do skanowania i upraszczania. Dzisiejszy problem jest głębszy: to system sam generuje materiał na teorie spiskowe, a robi to z autorytetem algorytmu.
Badacze ze Stanford kończą swój raport ostrożnym optymizmem: “jeśli społeczność badawcza zjednoczy się wokół wspólnego celu uczynienia generatywnych wyszukiwarek bardziej wiarygodnymi, myślę że sprawy się poprawią”. Chciałbym podzielać ten optymizm. Ale obserwując kierunek walki pomiędzy OpenAI, Google, Anthropic i wprowadzaniem biznesowo niedopracowanych narzędzi… czyli koncentracja, zamknięte modele, wyścig o engagement zamiast o prawdę - mam dosyć poważne wątpliwości. Uważność w dobie szybkiego konsumowania treści nie jest też umiejętnością łatwą.
Pamiętajmy, że filozofowie królowie, którym zamarzyło się ustawianie semantyki, a tym samym koncepcja szlachetnego kłamstwa muszą coś jeść, spółki muszą mieć dochód. A my musimy mieć wiedzę, żeby odróżnić mit od faktu. Tyle że tej wiedzy nikt nam nie dostarczy za sprawą magii promptowania… nadal trzeba ją zdobyć samemu, zanim zapytamy maszynę. A może powinniśmy spytać wprost, czy chcemy jeszcze uważności i krytyczności, czy może atrakcyjniejszy dla nas jest świat pozoru?
Żeby być uczciwym: materiały do nadchodzącego artykułu o Everbridge oraz ich systemach zbierałem z pomocą research-AI, które potem weryfikowałem. Test SERP z “EFF everbridge” robiłem z ciekawości, żeby zobaczyć jak zachowuje się tryb AI.
Warte uwagi źródła
Epistemic Injustice in Generative AI
STANDFORD UNIVERSITY: Liu, N.F., Zhang, T., & Liang, P. (2023) Evaluating Verifiability in Generative Search Engines | GitHub
Nie ma dla mnie znaczenia, iż tekst jest sprzed 2 lat jak widać tezy są nadal aktualne, a winę za to ponoszą firmy wdrażające niedopracowane technologie dla konsumentów i firm.





