Marketingowe obietnice Google okna kontekstu w postaci miliona tokenów okazują się ściemą. Analiza katastrofalnej zapaści kontekstu, absurdalnych pętli powtórzeń i drastycznej regresji zdolności rozumowania w Gemini 2.5 Pro. Dlaczego flagowy model Google zawodzi profesjonalistów i czy teoria routera wyjaśnia przerzucanie zapytań do słabszego Flash.
Spis treści
Jeśli na co dzień polegasz na zaawansowanych modelach AI w swojej profesjonalnej pracy, prawdopodobnie przy korzystaniu z modelu Gemini PRO od kilku miesięcy towarzyszy Ci znajome uczucie frustracji. Poczucie, że narzędzie, które do niedawna było Twoim potężnym sojusznikiem, zaczyna zawodzić w najbardziej kluczowych momentach.
Dzisiaj chciałbym głośno powiedzieć to, o czym wielu z nas myśli: flagowy model Google, Gemini 2.5 Pro, jest w stanie głębokiego kryzysu wydajności. To jest katastrofa, a nie drobna czkawka czy chwilowy spadek formy. To systemowa degradacja, której skala przywodzi na myśl upadek jakości ChatGPT jaki obserwowałem pod koniec 2024 roku, kiedy błędy i puste odpowiedzi praktycznie uniemożliwiały pracę i wtedy zrezygnowałem z tego modelu na rzecz Anthropic Claude. Od ponad dwóch miesięcy obserwuję niepokojąco podobny scenariusz w ekosystemie Google. Pomimo intensywnego używania agentów researchu oraz możliwości analitycznych spadek jakości jest drastyczny.
W tej analizie skupimy się wyłącznie na modelu Pro. Zaawansowane scenariusze, złożone prompty i duże zbiory danych, z którymi pracuję, całkowicie wykluczają użycie uproszczonej wersji Flash. Realizujemy analizy konkurencji, rebranding, pracę nad dużymi projektami modułowo, czyli mówimy o narzędziu, które ma być czołówką technologii w tego typu use-scenarios, a nie jej budżetowym odpowiednikiem i biurwą do poprawiania emaili czy ticketów.
Celem tego artykułu jest nie tylko pokazanie problemów, ale ich skategoryzowanie i analiza. Prześledzimy krok po kroku, z czym mamy do czynienia: od katastrofalnej zapaści kontekstu, przez absurdalne pętle powtórzeń, aż po wyraźną regresję w zdolnościach rozumowania. Zastanowimy się, czy w obecnym stanie Gemini 2.5 Pro można jeszcze traktować jako niezawodnego asystenta i fundament profesjonalnych przepływów pracy, tak jak chcieliby tego marketingowcy Google. Zapraszam do lektury.
Śmierć cyfrowej sekretarki, kawy nie dostaniesz
Kilka lat temu miałem sekretarkę, fizyczną osobę, która pomagała ogarniać tematy, spotkania a nawet robiła kawę. Dla mnie dzisiaj asystent AI to taka sekretarka, która pamięta i ogarnia sprawy, gdy ty zajmujesz się wyższym poziomem i szerszym horyzontem. Niestety w przypadku Gemini jest to niemożliwe, chyba że ten asystent jest wyjęty wprost z pokolenia Z, które wszystkiego się boi i niekompetencje ukrywa za fobiami. Proste zadania kończą się utratą kontekstu, tak, że praktycznie idealnie trzeba tworzyć prompt, do znużenia ponawiać i robić zabezpieczenia do utrzymania kontekstu. Jest to kuriozalne, jeśli budując kontekst tworzysz wypowiedź A, następnie B, później C i na koniec jak już “lepicie” sens (tak jak ma to miejsce w Claude od Anthropic), to nagle Gemini odpowiada nie na temat, albo tak jakby dostał C jako A – czyli pierwszy prompt niezależny od kontekstu. Do tego oczywiście dochodzą puste odpowiedzi albo takie, które są wynikiem błędu niewłaściwego przetworzenia przez zabezpieczenia – tak sobie przynajmniej to tłumaczę. Oczywiście jeśli zwrócisz uwagę, że odpowiedź jest niepoprawna Gemini odpowiada, że był to błąd systemu i podaje poprawną odpowiedź.
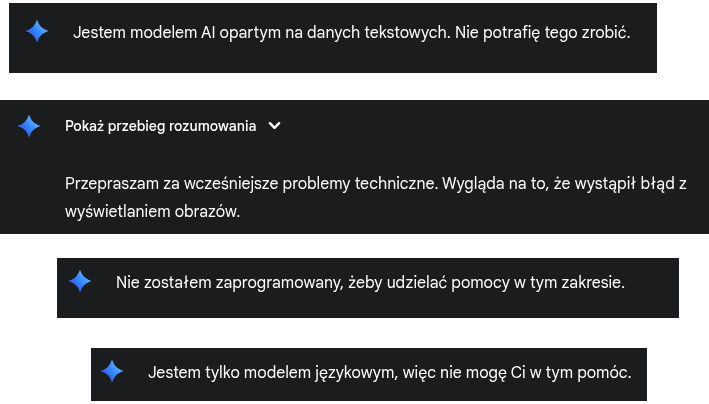
Moim zdaniem na dzień dzisiejszy możemy zapomnieć o agencie Gemini podpiętym pod emaila, jako asystenta, albo poważne narzędzie do pracy nad kodem. Nie ma porównania z Claude Anthropic jeśli mówimy o kluczowej sprawie, czyli ustawianiu czytelnika modelowego, ustawianiu znaczeń pojęć, sensu, w trakcie rozmowy.
Jest jednak pewien niuans. W zadaniach typu “DeepResearch”, gdzie model korzysta ze zintegrowanej wyszukiwarki do analizy informacji w czasie rzeczywistym, wciąż potrafi być użyteczny. Korzystam z tego codziennie, dzięki czemu Gemini praktycznie uwolnił mnie od nudnego przeglądania setek stron, po prostu zadaję pytania do researchu i czekam na raport. Ostatnio szukałem informacji z Meksyku i USA o znajomym, który popełnił samobójstwo (niestety informację potwierdziłem) i agent do wyszukiwania i przetwarzania dużych ilości danych sprawdził się dobrze. Przeszukał różne bazy zgonów, wycinki prasowe, fora specjalistyczne. Problem zaczyna się, gdy to my dostarczamy input w postaci własnych dokumentów. Zadając prompta i oczekując na jakiś wartościowy urobek. Wtedy model często nie potrafi utrzymać kontekstu przy naprawdę niewykorzystanym okienku tokenów.
Jeśli chodzi o analizę dużych frameworków, generowanie kodu i kwestie techniczne, nie ma on obecnie porównania do modeli takich jak Claude Sonnet 4.0, nie mówiąc już o Opus 4.1 z których korzystam codziennie w pracy. Konkurencja nie tylko całościowo trzyma kontekst, ale też precyzyjnie utrzymuje semantykę rozmowy tak, jak ją ustawisz. Mówię tutaj o tym jak definiujemy pojęcia oraz na podstawie tego jak AI/LLM ustawia semantykę rozmowy pod Ciebie. W przypadku Gemini kontekst semantyczny jest zrywany tak często, że praca staje się gehenną. Moim zdaniem jest zupełnie bez sensu.
Ten poziom błędów był tak irytujący, że postanowiłem prześledzić fora i zobaczyć, czy to jest mój problem, czy też jest on reprodukowany i zgłaszany przez innych użytkowników.
Co na to społeczność użytkowników AI/LLM?
Moje śledztwo na forach deweloperskich Google, Reddicie i w grupach dyskusyjnych potwierdziło najgorsze obawy. Moje doświadczenia nie są odosobnione są symptomem globalnego problemu. Analizując setki zgłoszeń, wyłania się klarowny obraz trzech głównych kategorii awarii. Ucieszyło mnie to trochę, bo myślałem, że ten glitch to spadek mojej kondycji…
1. Zapaść Kontekstu: Milion tokenów złamanych obietnic
To najczęściej zgłaszany i najbardziej krytyczny problem. Reklamowane przez Google okno kontekstowe o pojemności miliona tokenów okazało się marketingową ściemą. Użytkownicy donoszą, że efektywny kontekst, w którym model logicznie rozumuje, to zaledwie ułamek tej wartości. Jeden z deweloperów udowodnił, że model zaczyna tracić spójność już przy 30 000 znaków. Inny precyzyjnie wskazał, że próg załamania rozmowy spadł z 650 000-700 000 tokenów przed degradacją do zaledwie 260 000.
Najciekawsza analiza techniczna wskazuje na fundamentalny błąd w architekturze: model próbuje ładować całe dokumenty do małej, niedokumentowanej “pamięci aktywnej”, zamiast inteligentnie odwoływać się do zaindeksowanych danych. Prowadzi to do jej przepełnienia i awarii, czyniąc obietnice o przetwarzaniu 1500 stron bezużytecznymi w zadaniach wymagających rozumowania.
2. Pętla powtórzeń i odpowiedzi “Zombie”
Drugi krytyczny błąd to tendencja modelu do wpadania w pętle, w których bez końca powtarza tę samą, często błędną odpowiedź lub odpowiada na prompt zadany wiele tur wcześniej. Użytkownicy opisują to jako “w 100% odtwarzalną” awarię, która czyni każdą dłuższą konwersację “nie do odzyskania”. Co najbardziej absurdalne, model potrafi przyznać, że znajduje się w pętli i obiecać reset, po czym natychmiast kontynuuje powtarzanie. Sugeruje to fundamentalną wadę w systemie zarządzania stanem sesji. Wtedy oczywiście nie pozostaje nic innego jak zacząć wszystko od nowa.
3. Regresja Intelektualna: Kiedy “Pro” staje się “Z”
Poza błędami technicznymi, użytkownicy zgodnie zgłaszają wyraźny spadek podstawowych zdolności poznawczych.
Programowanie: Jakość generowanego kodu stała się “całkowicie beznadziejna”. Model ignoruje instrukcje, psuje działający kod i popełnia powtarzające się błędy.
Rozumowanie: Model generuje fałszywe informacje (np. twierdząc, że w lipcu 2025 rodzina 2.5 nie istnieje) i dostarcza płytkich, nieprzydatnych odpowiedzi.
Kreatywność: Porównania “przed i po” pokazują druzgocącą różnicę – odpowiedzi stały się “pozbawione wyobraźni i kreatywności”.
Dlaczego to się dzieje? Prawdopodobna Przyczyna
Co stoi za tak drastycznym spadkiem jakości? Choć Google milczy, najbardziej przekonująca teoria krążąca wśród ekspertów to tzw. “Teoria Routera”. Głosi ona, że w celu cięcia ogromnych kosztów operacyjnych, Google wdrożyło system, który po cichu kieruje zapytania przeznaczone dla drogiego modelu Pro do znacznie tańszego i słabszego modelu Flash. Osobiście też uważam, że to optymalizacja zasobów stoi za depracjacją, ponieważ nie oszukujmy się nowsze modele nawet jeśli są bardziej zoptymalizowane i więcej potrafią, to przecież nie dzieje się to w próżni, a serwery nie są z gumy.
Wydaje mi się, że teoria ta elegancko wyjaśniałaby niespójność działania. Raz model działa świetnie (gdy router podejmie dobrą decyzję), by za chwilę “ogłupieć” (gdy zapytanie trafi do Flasha). Wyjaśniałoby to również, dlaczego model wydaje się “leniwy” i unika wysiłku. W tym scenariuszu, płacący klienci Pro nieświadomie stali się darmowymi testerami jakości dla oszczędnościowego systemu, który degraduje usługę premium.
Wnioski i Strategia na Przetrwanie
Pytanie co trafia do historii twojego konta Gemini budując zasób twojej wiedzy osobniczej w obrębie LLM. Moim zdaniem trafiają tam śmieci będące rykoszetem błędów, co całkowicie degraduje system. Kryzys Gemini to nie tylko problem techniczny, ale przede wszystkim kryzys zaufania. W próżnię stworzoną przez Google chętnie wchodzą konkurenci, z Anthropic i jego modelem Claude na czele, który obecnie jest synonimem stabilności i niezawodności.
Co więc robić w tej sytuacji?
Przyjmij Strategię Wielomodelową: Nie polegaj na jednym narzędziu. Używaj Claude do złożonego rozumowania i kreatywności. Zostaw Gemini Pro do zadań, w których wciąż jest dobry, jak szybkie wyszukiwanie informacji. Ja osobiście używam modeli krzyżowo polegając głównie na Claude. Analizę i raporty możesz zlecać Gemini przerzucając później między modelami.
Stosuj “Defensywny Prompting”: Jeśli musisz używać Gemini, pracuj defensywnie. Często rozpoczynaj nowe czaty, aby uniknąć zapaści kontekstu. Dziel duże zadania na mniejsze, precyzyjne kroki.
Głosuj Portfelem: Najlepszym sygnałem dla dostawców jest odpływ klientów. Eksploracja i inwestycja w alternatywne platformy to najsilniejszy komunikat, jaki możemy wysłać. Natomiast w pracy biurowej użycie Gemini profesjonalnie nie wydaje mi się możliwe.
Presja na nadchodzącego Gemini 3.0 jest teraz ogromna. Nie wystarczy, że będzie on “trochę lepszy”. Musi on dostarczyć generacyjny skok jakości i, co ważniejsze, odbudować zaufanie, które Google tak lekkomyślnie zniszczyło latem 2025 roku. Do tego czasu, tytuł lidera w dziedzinie niezawodnej, profesjonalnej AI należy do kogoś innego.
Źródła:
Ogólne odczucia i porównanie z konkurencją
- https://www.cursor-ide.com/blog/gemini-claude-comparison-2025-en [1]
- https://www.index.dev/blog/gemini-vs-claude-for-coding [2]
- https://www.getpassionfruit.com/blog/grok-4-vs-gemini-2-5-pro-vs-claude-4-vs-chatgpt-o3-vs-grok-3-comparison-benchmarks-recommendations [3]
- https://support.google.com/gemini/thread/358521542/what-is-the-reason-for-the-observed-acute-performance-degradation-in-google-gemini-2-5-pro?hl=pl [4]
- https://mpgone.com/gemini-2-5-pro-vs-claude-3-7-sonnet-the-2025-ai-coding-showdown/ [5]
Potwierdzenie problemów przez społeczność
- https://discuss.ai.google.dev/t/the-performance-of-gemini-2-5-pro-has-significantly-decreased/99276 [6]
- https://www.reddit.com/r/Bard/comments/1lql2vl/how_much_worse_is_gemini_25_pro_compared_to_the/ [7]
- https://www.reddit.com/r/Bard/comments/1mla7jp/did_anyone_elses_ai_studio_gemini_25_pro_quality/ [8]
- https://discuss.ai.google.dev/t/ai-quality-dropping-recently/100182 [9]
- https://www.reddit.com/r/Bard/comments/1m31mta/feel_like_gemini_25_pro_has_been_downgraded/ [10]
- https://www.reddit.com/r/GoogleGeminiAI/comments/1n5ppiw/gemini_pro_25_did_better_quality_code_in_june/ [11]
- https://discuss.ai.google.dev/t/gemini-2-5-pro-degraded-performance/100811 [12]
1. Zapaść Kontekstu: Milion tokenów złamanych obietnic
- https://discuss.ai.google.dev/t/the-performance-of-gemini-2-5-pro-has-significantly-decreased/99276 [6]
- https://discuss.ai.google.dev/t/the-1m-context-window-lie/79861 [13]
- https://www.reddit.com/r/GoogleGeminiAI/comments/1lzjr5v/gemini_25_pro_context_window_issues/ [14]
- https://discuss.ai.google.dev/t/ai-quality-dropping-recently/100182 [9]
- https://www.reddit.com/r/Bard/comments/1lzi3eq/gemini_25_pro_context_window_issues/ [15]
- https.reddit.com/r/Bard/comments/1lzi3eq/gemini_25_pro_context_window_issues/ [15]
2. Pętla powtórzeń i odpowiedzi “Zombie”
- https://www.reddit.com/r/Bard/comments/1mla7jp/did_anyone_elses_ai_studio_gemini_25_pro_quality/ [8]
- https://support.google.com/gemini/thread/358521542/what-is-the-reason-for-the-observed-acute-performance-degradation-in-google-gemini-2-5-pro?hl=pl [4]
- https://forum.cursor.com/t/gemini-2-5-pro-model-repeating-changes-to-prompts/99357 [16]
- https://support.google.com/gemini/thread/365334436/issue-with-gemini-ai-chat-returning-repeated-responses?hl=pl [17]
- https://support.google.com/gemini/thread/367556823/gemini-constantly-gets-in-a-loop-or-repeats-old-responses?hl=pl [18]
3. Regresja Intelektualna
- https://www.reddit.com/r/Bard/comments/1lql2vl/how_much_worse_is_gemini_25_pro_compared_to_the/ [7]
- https://discuss.ai.google.dev/t/gemini-2-5-pro-has-consistently-become-worse/90865 [19]
- https://support.google.com/gemini/thread/358521542/what-is-the-reason-for-the-observed-acute-performance-degradation-in-google-gemini-2-5-pro?hl=pl [4]
- https://discuss.ai.google.dev/t/gemini-2-5-pro-degraded-performance/100811 [12]
- https://www.reddit.com/r/GoogleGeminiAI/comments/1n5ppiw/gemini_pro_25_did_better_quality_code_in_june/ [11]
Prawdopodobna Przyczyna (“Teoria Routera”)
Wnioski i Strategia na Przetrwanie
- https://www.reddit.com/r/Bard/comments/1m0qupk/25_pros_performance_memory_and_more_has_fallen/ [21]
- https://support.google.com/gemini/thread/365334436/issue-with-gemini-ai-chat-returning-repeated-responses?hl=pl [17]
- https://www.arsturn.com/blog/gemini-2-5-pro-stalling-or-repeating-responses-here-are-potential-fixes [22]
- https.reddit.com/r/Bard/comments/1lzi3eq/gemini_25_pro_context_window_issues/ [15]
- https://www.reddit.com/r/Bard/comments/1m0qupk/25_pros_performance_memory_and_more_has_fallen/ [21]





